Vitalik responds to Musk: Improving blockchain scalability is not simple

 As the capacity increases, the minimum number of nodes will also increase, and the cost of the archive chain (if no one takes the trouble to manage the archive chain, the risk of data loss increases) will also rise.
As the capacity increases, the minimum number of nodes will also increase, and the cost of the archive chain (if no one takes the trouble to manage the archive chain, the risk of data loss increases) will also rise.This article is authored by Vitalik Buterin and compiled by Alyson.
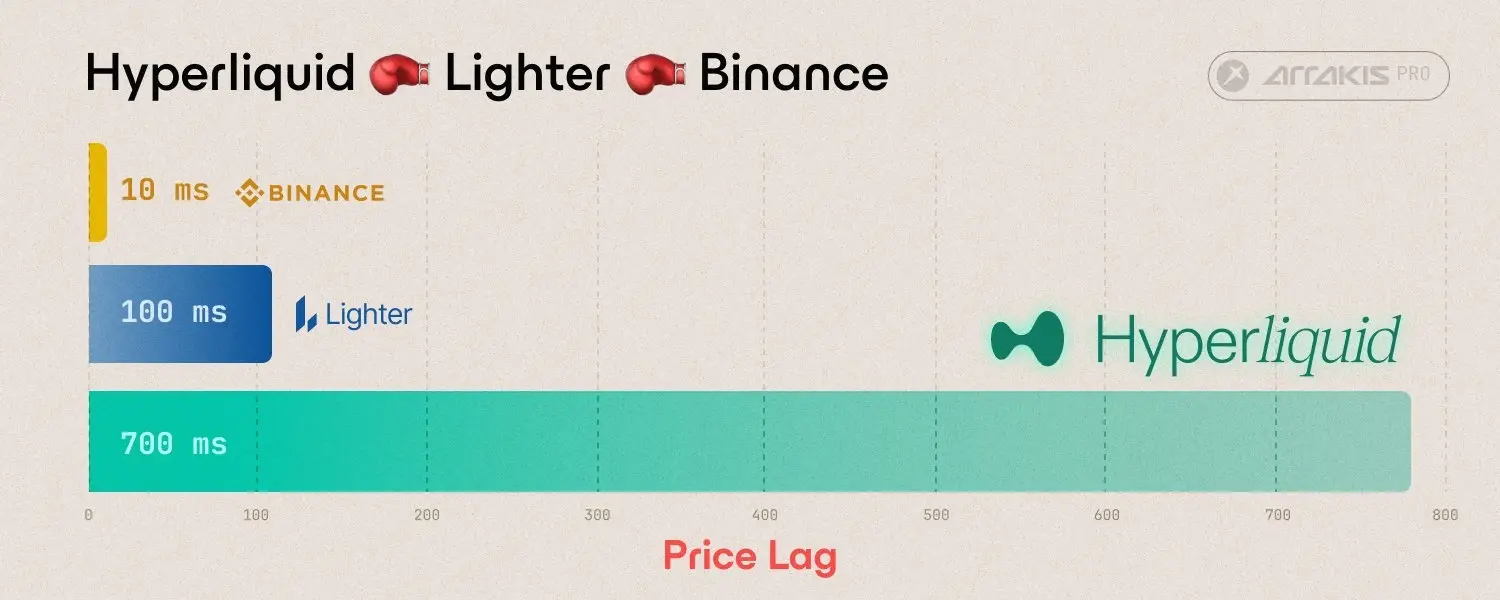
Recently, Tesla founder Elon Musk tweeted that Dogecoin could ideally speed up block confirmation times by 10 times, increase block sizes by 10 times, and reduce transaction fees by 100 times, after which it would easily win.
This statement has drawn criticism from many KOLs in the crypto industry. Ethereum founder Vitalik also wrote about this matter today, stating that simply increasing blockchain network parameters would lead to more trouble, and elaborated on the issues and limitations that need to be addressed when improving blockchain network performance. Therefore, Chain Catcher has translated this article and made edits that do not affect the original meaning.
How far can you push the scalability of blockchain? As Musk hopes, can you truly achieve "reducing block confirmation times by 10 times, increasing block sizes by 10 times, and reducing transaction fees by 100 times" without leading to extreme centralization and compromising the fundamental properties of blockchain? If not, how far can you go? What if you change the consensus algorithm? More importantly, what happens if you change the technology to introduce features like ZK-SNARKs or sharding?
It turns out that there are significant and quite subtle technical factors that limit the scalability of blockchain, regardless of sharding. In many cases, there are solutions to these limitations, but even with solutions, there are constraints. This article will explore these issues.
1. Nodes Need to Be Sufficiently Decentralized
At 2:35 AM, you receive an urgent call from a partner on the other side of the world who helps you manage a mining pool (or possibly a staking pool). About 14 minutes ago, your partner informed you that your mining pool and several others have separated from the blockchain that still carries 79% of the network. According to your node, the majority chain's blocks are invalid. There is a balance error: a critical block seems to have incorrectly allocated 4.5 million extra tokens to an unknown address.
An hour later, you are chatting on Telegram with two other small mining pools. You eventually see someone paste a link to a tweet that contains a published message. The tweet begins with "Announcing a new on-chain sustainable protocol development fund."
By morning, debates on Twitter and community forums are everywhere. However, by then, a large portion of those 4.5 million tokens has already been converted to other assets on-chain and has undergone billions of dollars in DeFi transactions. 79% of the consensus nodes, along with all major blockchain explorers and light wallet nodes, are following this new chain.
Perhaps the new developer fund will finance some developments, or perhaps all of this will be swallowed up by leading exchanges. Regardless of the outcome, the fund is a fait accompli for all intents and purposes, and ordinary users are powerless to fight back.
Can this happen on your blockchain? The elites in your blockchain community may coordinate well, including mining pools, block explorers, and hosted nodes. They are likely all in the same Telegram channel and WeChat group. If they truly want to make sudden changes to the protocol rules to benefit themselves, they might do so. The only reliable way to render such a coordinated social attack ineffective is through passive defense, where this group is actually decentralized: the users.
Imagine if users were running validating nodes for the blockchain and automatically rejecting blocks that violate protocol rules (even if over 90% of miners or stakeholders support them), how would the story unfold? If every user runs a validating node, then the attack would quickly fail: some mining pools and exchanges would fork off in the process, looking quite foolish.
However, even if some users run validating nodes, the attack would not lead to a complete victory for the attackers; rather, it would cause chaos, with different users seeing different views of the blockchain. At the very least, the ensuing market panic and potential ongoing splits would greatly reduce the attackers' profits. The very idea of navigating such a protracted conflict would deter most attacks.
Twitter of Hasu, research partner at Paradigm
If you have a community of 37 nodes running programs and 80,000 passive listening programs to check signatures and block headers, the attackers win. If everyone in your community runs a node, then the attackers fail. We do not know the exact threshold for group immunity against coordinated attacks, but one thing is absolutely clear: more nodes are good, fewer nodes are bad, and we definitely need dozens or hundreds of nodes.
2. Where Are the Limits of Node Work?
To maximize the number of users who can run nodes, we will focus on conventional consumer-grade hardware. The ability of a full node to handle a large number of transactions has three key limitations:
Computing power: What percentage of CPU capacity is required to securely run a node?
Bandwidth: Given the current realities of internet connections, how many bytes can a block contain?
Storage: How many GB of disk space can we reasonably ask users to store? Additionally, how fast must it be to read? (Can we use hard drives, or do we need solid-state drives?)
Many people mistakenly believe that using "simple" technology can extend the scalability of blockchain, due to overly optimistic views of these numbers. We can examine the following three factors one by one:
1) Computing Power
Wrong answer: 100% of CPU capacity can be spent on block validation.
Correct answer: About 5-10% of CPU capacity can be used for block validation.
The main reasons for such a low limitation ratio are fourfold:
We need a safety margin to cover the possibility of DoS attacks (transactions that exploit code vulnerabilities take longer to process than regular transactions);
Nodes need to be able to synchronize the blockchain after going offline. If I disconnect from the network for a minute, I should be able to catch up in seconds;
Running a node should not quickly drain battery power, slowing down all other applications;
Nodes also need to perform other non-block production tasks, primarily around validating and responding to incoming transactions and requests on the p2p network.
Note that until recently, most explanations for "why only 5-10%?" focused on a different issue: since PoW blocks appear randomly, the time taken to validate blocks increases the risk of multiple blocks being created simultaneously.
There are many ways to address this issue (e.g., Bitcoin NG or using proof-of-stake mechanisms). However, these patches do not solve the other four problems, so they cannot bring the significant scalability benefits that many initially thought.
Parallelism is not a panacea either. Typically, even seemingly single-threaded blockchain clients have already been parallelized: signatures can be validated by one thread, while execution is handled by other threads, and there is a separate thread handling transaction pool logic in the background. Moreover, the closer to 100% utilization of all threads, the more energy consumed by running the node, and the lower the safety margin against DoS attacks.
2) Bandwidth
Wrong answer: If we have 10 MB data blocks every 2-3 seconds, most users' network speeds are > 10 MB/s, so they can certainly handle it.
Correct answer: Perhaps we can handle 1-5 MB blocks every 12 seconds, although it is difficult.
Nowadays, we often hear advertising statistics about how much bandwidth internet connections can provide: numbers like 100 Mbps or even 1 Gbps are commonly heard. However, there is a significant difference between advertised bandwidth data and actual bandwidth for several reasons:
"Mbps" refers to "millions of bits per second," and a bit is 1/8 of a byte, so the advertised bit count must be divided by 8 to get the advertised byte count;
Like all companies, internet service providers often lie;
There are always multiple applications using the same internet connection, so nodes cannot monopolize the entire bandwidth;
P2P networks inevitably bring their own overhead: nodes often download and re-upload the same block multiple times (not to mention transactions broadcast through the mempool before being included in blocks).
When Starkware conducted experiments in 2019, they first released a 500 kb block because the reduced gas costs of transactions made this possible for the first time, and in fact, several nodes could not handle blocks of that size.
Since then, the ability of blockchains to handle large data blocks has improved and will continue to improve. But no matter what we do, we are still far from naively obtaining average bandwidth in MB/s, convincing ourselves that we can tolerate 1s of latency, and being able to handle such large data blocks.
3) Storage
Wrong answer: 10TB.
Correct answer: 512GB.
As you might guess, the main argument here is the same as elsewhere: the difference between theory and practice. Theoretically, you can buy an 8 TB solid-state drive on Amazon. In practice, the laptop used to write this blog post has 512 GB, and if you ask people to buy their own hardware, many of them will become lazy (or they cannot afford an $800 8TB solid-state drive) and will use centralized vendors.
Moreover, even if you can install and run block nodes on some storage disks, high levels of activity can quickly burn out the disks, forcing you to constantly buy new ones.
Additionally, the size of storage determines how long it takes for new nodes to come online and start participating in the network. Any data that existing nodes must store is data that new nodes must download. The initial synchronization time (and bandwidth) is also a major barrier for users running nodes. When writing this blog, it took me about 15 hours to synchronize a new geth node.
3. Risks of Sharded Blockchains
Today, running a node on the Ethereum blockchain poses challenges for many users. Thus, we encounter bottlenecks. The core developers' primary concern is storage size. Therefore, current efforts to address computational and data bottlenecks, even changes to the consensus algorithm, are unlikely to lead to a significant increase in gas limits. Even if the most prominent DoS vulnerabilities in Ethereum are resolved, the gas limit can only increase by about 20%.
The only way to address the storage size issue is through statelessness and state expiration. Statelessness allows a class of nodes to validate the blockchain without maintaining permanent storage. State expiration clears recently unaccessed states, forcing users to manually provide proof of renewal.
Both paths have been in use for a long time, and proof-of-concept implementations of statelessness have already begun. Combining these two improvements can greatly alleviate these concerns and open up space for significantly increasing gas limits. However, even after implementing statelessness and state expiration, the gas limit may only be safely increased by about three times until other limitations begin to dominate.
Sharding fundamentally circumvents the above limitations by decoupling the data contained on the blockchain from the data that a single node needs to process and store. They use advanced mathematics and cryptographic techniques to indirectly validate blocks, rather than having nodes verify blocks by personally downloading and executing them.
Thus, sharded blockchains can safely achieve transaction throughput levels that non-sharded blockchains cannot reach. This indeed requires a great deal of cryptographic ingenuity to create efficient and simple fully validating methods that successfully reject invalid blocks, but it is achievable: the theory is well-developed, and proof-of-concept based on draft specifications is already underway.
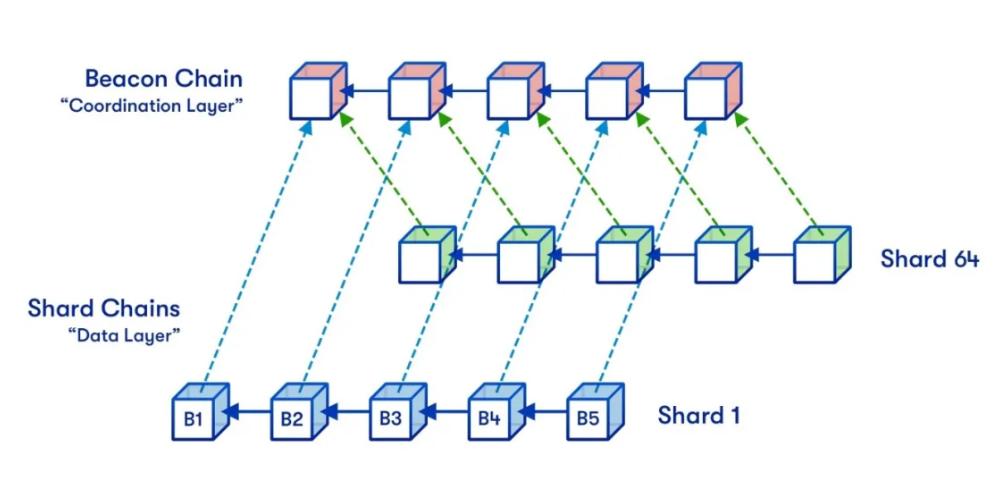
Ethereum plans to use quadratic sharding, as nodes must be able to handle individual shards and the beacon chain (which must perform a certain amount of management work for each shard), so overall scalability is limited. If shards are too large, nodes will no longer be able to process individual shards; if there are too many shards, nodes will no longer be able to handle the beacon chain. The product of these two constraints forms an upper limit.
It is conceivable that by implementing cubic sharding or even exponential sharding, we could go further. In such designs, data availability sampling would certainly become much more complex, but it is doable. However, Ethereum will not go beyond quadratic curves. The reason is that transaction sharding cannot achieve additional scalability gains unless other risks become very high.
So what are these risks?
1) Minimum Number of Users
It can be imagined that as long as there is one user willing to participate, a non-sharded blockchain can operate. Sharded blockchains are not like this: no single node can handle the entire blockchain alone, so a sufficient number of nodes are needed to work together. If each node can handle 50 TPS, and the blockchain needs to handle 10,000 TPS, then at least 200 nodes are needed on-chain to operate.
If the blockchain has fewer than 200 nodes at any time, then either the nodes cannot keep up with the blockchain, or they cannot detect invalid blocks, or many other adverse situations may occur, depending on how the node software is installed.
If the capacity of the sharded blockchain increases by 10 times, the minimum number of nodes will also increase by 10 times. Then, you might ask: why don’t we start with a little capacity and increase it when we see a large influx of users; and decrease capacity if the number of users drops? This way, we can grasp the part that actually needs it.
Here are some questions:
The blockchain itself cannot accurately detect how many unique nodes there are, so some governance will be needed to detect and set the number of shards. Exceeding capacity limits can easily become a source of splits and conflicts.
What if many users suddenly exit unexpectedly?
Increasing the minimum number of nodes required to launch a fork makes it more difficult to resist hostile takeovers.
It is almost certain that the minimum number of nodes should not exceed 1,000. Therefore, it seems difficult to justify a blockchain with hundreds of shards.
2) Historical Retrievability
A key attribute of blockchains that users truly value is permanence. When a company goes bankrupt or loses the ability to maintain the ecosystem, digital assets stored on servers will be cleared after 10 years. In contrast, NFTs on Ethereum are permanent.
Yes, people will still be downloading and retrieving your CryptoKitties in 2371.
However, once the blockchain capacity becomes too high, storing all this data becomes more challenging. If a significant risk occurs at some point, certain parts of history will have no one to store them.
Quantifying this risk is easy. Taking the data capacity of the blockchain (MB/s) and multiplying it by 30 gives the amount of data stored in TB per year. The current data capacity of the sharding plan is about 1.3 MB/s, which amounts to about 40 TB/year. If this is increased by 10 times, it will become 400 TB/year.
If we want the data to be not only accessible but also conveniently reachable, we also need metadata (e.g., decompressing rollup things), so we would need 4 PB per year, or 40 PB after 10 years. This is a reasonable upper limit that most sharded blockchains can safely achieve.
Thus, it appears that in these two dimensions, Ethereum's sharding design has indeed roughly aimed at a reasonably close maximum safe value. Parameters can be increased a bit, but not too much.
4. Conclusion
There are two approaches to attempting to scale blockchains: fundamental technical improvements and simple parameter increases. First, increasing parameters sounds appealing: if you do the math on a napkin, it is easy to convince yourself that a home laptop can handle thousands of transactions per second without needing ZK-SNARKs, rollups, or sharding. Unfortunately, this approach is fundamentally flawed for many subtle reasons.
Computers running blockchain nodes cannot expend 100% of CPU capacity to validate the blockchain; they need a significant safety margin to resist unexpected DoS attacks, and they need spare capacity to handle transactions processed in the memory pool. Moreover, users do not want to run nodes on computers that render those computers unusable for any other applications.
Bandwidth also has overhead: a 10 MB/s connection does not mean you can have 10 MB blocks every second; you may only be able to handle 1-5 MB blocks every 12 seconds, similar to storage. Increasing the hardware configuration for running nodes and limiting node operation to specific participants is not the solution. For a blockchain that aims to be decentralized, it is crucial that ordinary users can run nodes and that there is a common culture of running nodes.
Fundamental technical improvements are certainly effective. Currently, Ethereum's main bottleneck is storage capacity, and statelessness and state expiration can address this issue, allowing for an increase of up to about three times (but not exceeding 300 times), as we want running a node to become easier than it is now. Sharded blockchains can further scale because there are no single nodes that need to handle transactions in a sharded blockchain.
But even so, capacity is still limited: as capacity increases, the minimum number of nodes also increases, and the costs of archiving chains (if no one bothers to manage the archiving chain, the risk of data loss increases).
However, we need not worry too much: these limits are high enough that we can process over a million transactions per second on a blockchain while remaining completely secure. But achieving this without sacrificing the decentralization of the blockchain will require effort.
 Risk warning
Risk warning Risk warning
Risk warning