IOSG: Liberating Ethereum's Performance, An Innovative Path Beyond the EVM Bottleneck

 Why should all computations be on-chain? Is there a similarly trustless and decentralized execution system? This is what the DCompute system can achieve.
Why should all computations be on-chain? Is there a similarly trustless and decentralized execution system? This is what the DCompute system can achieve.Author: Siddharth Rao, IOSG Ventures
Liberating Ethereum Performance: An Innovative Path Beyond the EVM Bottleneck
On the Performance of the Ethereum Virtual Machine (EVM)
Every operation on the Ethereum mainnet incurs a certain amount of Gas. If we put all the computational load required for running basic applications on-chain, either the app will crash, or the users will go bankrupt.
This has led to the emergence of L2: OPRU introduced sorters to bundle a bunch of transactions and then submit them to the mainnet. This not only helps apps leverage Ethereum's security but also provides users with a better experience. Users can submit transactions faster, and the fees are cheaper. Although operations have become cheaper, it still uses the native EVM as the execution layer. Similar to ZK Rollups, Scroll and Polygon zkEVM use or will use EVM-based zk circuits, with zk Proofs generated for each transaction or a large batch of transactions processed by their provers. While this allows developers to build "fully on-chain" applications, can it still operate efficiently and economically for high-performance applications?
What Are These High-Performance Applications?
The first things that come to mind are games, on-chain order books, Web3 social, machine learning, genomic modeling, etc. All of these require significant computational power, and running them on L2 would also be very expensive. Another issue with the EVM is that its speed and efficiency of computation are not on par with other systems today, such as SVM (Sealevel Virtual Machine).
While L3 EVM can make computation cheaper, the structure of the EVM itself may not be the best way to execute high-computation tasks, as it cannot perform parallel computations. Each time a new layer is built on top, new infrastructure (a new node network) must be established to maintain the spirit of decentralization, which still requires the same number of providers to scale, or a whole new set of node providers (individuals/businesses) to provide resources, or both.
Therefore, whenever more advanced solutions are built, existing infrastructure must be upgraded, or a new layer must be built on top. To address this issue, we need a post-quantum secure, decentralized, trustless, high-performance computing infrastructure that can efficiently utilize quantum algorithms for decentralized applications.
Alt-L1s like Solana, Sui, and Aptos can achieve parallel execution, but due to market sentiment and a lack of liquidity, there is a shortage of developers in the market, and they do not pose a challenge to Ethereum. The lack of trust, combined with the moat built by Ethereum through network effects, is monumental. So far, there is no killer for ETH/EVM. The question here is, why should all computation be on-chain? Is there a similarly trustless, decentralized execution system? This is what the DCompute system can achieve.
The DCompute infrastructure aims to be decentralized, post-quantum secure, and trustless. It does not need to be or should not be blockchain/distributed technology, but verifying computation results, correct state transitions, and final confirmations is very important. The operation of EVM chains is such that while maintaining the security and immutability of the network, decentralized, trustless, and secure computation can be moved off-chain.
What we primarily overlook here is the issue of data availability. This article does not ignore data availability, as solutions like Celestia and EigenDA are already developing in this direction.
1: Only Compute Outsourced
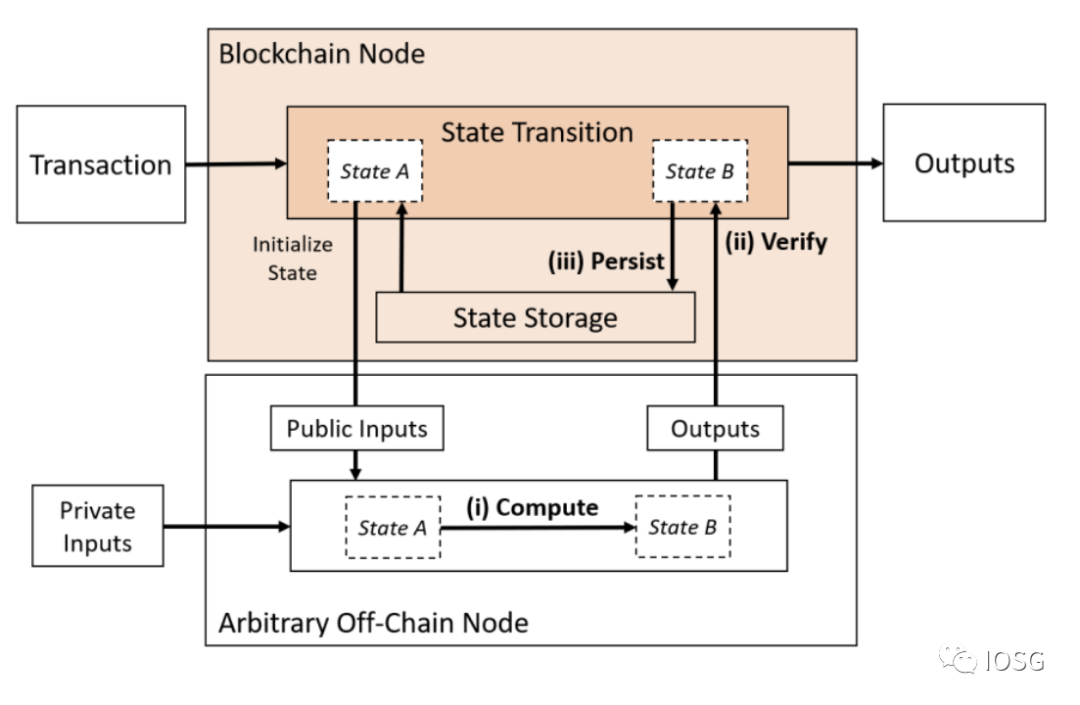
(Source: Off-chaining Models and Approaches to Off-chain Computations, Jacob Eberhardt & Jonathan Heiss)
2. Outsourcing Computation with Data Availability
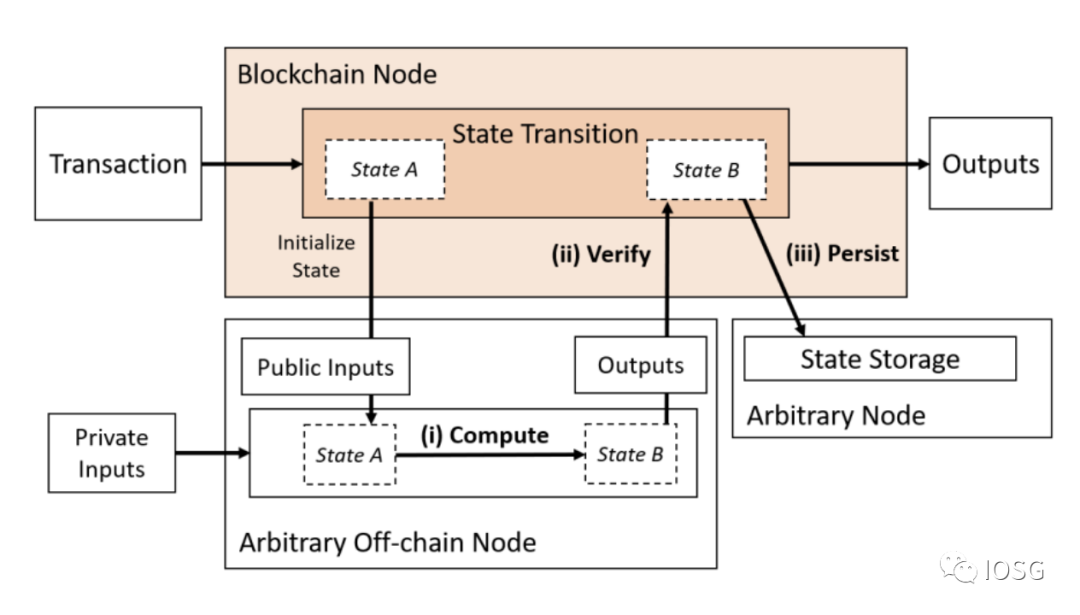 (Source: Off-chaining Models and Approaches to Off-chain Computations, Jacob Eberhardt & Jonathan Heiss)
(Source: Off-chaining Models and Approaches to Off-chain Computations, Jacob Eberhardt & Jonathan Heiss)
When we look at Type 1, zk-rollups are already doing this, but they are either limited by the EVM or require teaching developers to learn a completely new language/instruction set. The ideal solution should be efficient, effective (in terms of cost and resources), decentralized, private, and verifiable. ZK proofs can be built on AWS servers, but they are not decentralized. Solutions like Nillion and Nexus are attempting to address the problem of general computation in a decentralized manner. However, these solutions are unverifiable without ZK proofs.
Type 2 combines off-chain computation models with a separate data availability layer, but computation still needs to be verified on-chain.
Let’s take a look at the different decentralized computing models that are partially trusted and potentially completely trustless available today.
Alternative Computation Systems
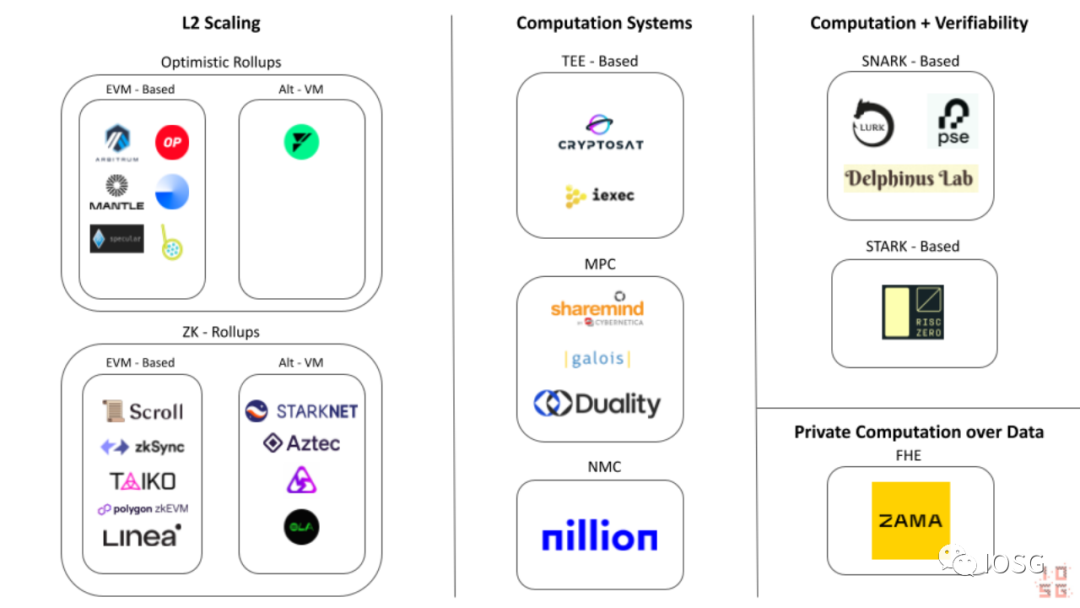
Ethereum Outsourced Computing Ecosystem Diagram (Source: IOSG Ventures)
- Secure Enclave Computations / Trusted Execution Environments
TEEs (Trusted Execution Environments) are like a special box inside a computer or smartphone. They have their own locks and keys, and only specific programs (called trusted applications) can access them. When these trusted applications run inside the TEE, they are protected from other programs and even the operating system itself.
It’s like a secret hideout that only a few special friends can enter. The most common examples of TEEs are secure enclaves that exist on the devices we use, such as Apple’s T1 chip and Intel’s SGX, which are used to perform critical operations like FaceID within the device.
Since TEEs are isolated systems, the authentication process cannot be compromised because there is a trust assumption in the authentication. You can think of it as having a secure door that you trust is safe because Intel or Apple built it, but there are enough security breakers (including hackers and other computers) in the world that can compromise that secure door. TEEs are not "post-quantum secure," meaning that quantum computers with unlimited resources can break the security of TEEs. As computers rapidly become more powerful, we must keep post-quantum security in mind when building long-term computing systems and cryptographic schemes.
- Secure Multi-Party Computation (SMPC)
SMPC (Secure Multi-Party Computation) is also a well-known computing scheme in the blockchain technology field. The general workflow in an SMPC network consists of the following three parts:
- Step 1: Convert the input of the computation into shares and distribute them among SMPC nodes.
- Step 2: Perform the actual computation, usually involving message exchanges between SMPC nodes. At the end of this step, each node will have a share of the computed output value.
- Step 3: Send the result shares to one or more result nodes, which run LSS (Secret Sharing Recovery Algorithm) to reconstruct the output result.
Imagine an automobile assembly line where the construction and manufacturing components (engine, doors, mirrors) are outsourced to original equipment manufacturers (OEMs) (working nodes), and then there is an assembly line that puts all the components together to manufacture the car (result nodes).
Secret sharing is crucial for protecting privacy in decentralized computing models. It prevents a single participant from obtaining the complete "secret" (in this case, the input) and maliciously producing incorrect outputs. SMPC may be one of the easiest and safest decentralized systems. While there is currently no fully decentralized model, it is logically possible.
MPC providers like Sharemind provide MPC infrastructure for computation, but the providers are still centralized. How to ensure privacy, and how to ensure that the network (or Sharemind) does not have malicious behavior? This is where zk proofs and zk verifiable computation come into play.
- Nil Message Compute (NMC)
NMC is a new distributed computing method developed by the Nillion team. It is an upgrade of MPC where nodes do not need to communicate through result exchanges. To achieve this, they use a cryptographic primitive called One-Time Masking, which utilizes a series of random numbers called blinding factors to mask a Secret, similar to a one-time pad. OTM aims to provide correctness in an efficient manner, meaning NMC nodes do not need to exchange any messages to perform computations. This means NMC does not have the scalability issues of SMPC.
- Zero-Knowledge Verifiable Computation
ZK Verifiable Computation (ZKVC) generates zero-knowledge proofs for a set of inputs and a function, proving that any computation executed by the system is performed correctly. Although ZK verifiable computation is a nascent concept, it is already a very critical part of the Ethereum network's scaling roadmap.
ZK proofs come in various implementations (as summarized in the following diagram from the paper "Off-Chaining Models"):
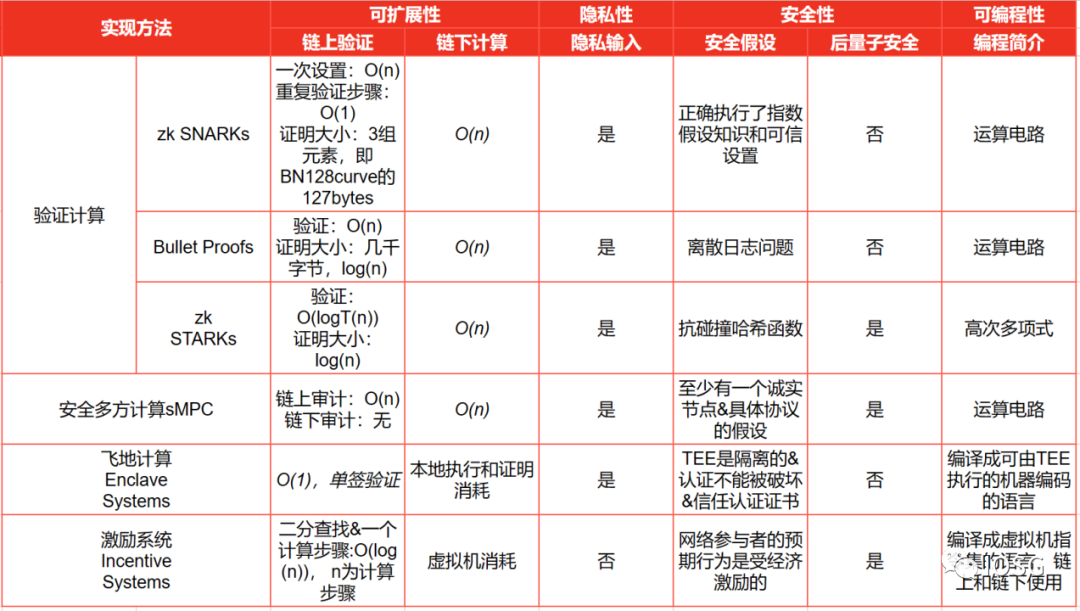 (Source: IOSG Ventures, Off-chaining Models and Approaches to Off-chain Computations, Jacob Eberhardt & Jonathan Heiss)
(Source: IOSG Ventures, Off-chaining Models and Approaches to Off-chain Computations, Jacob Eberhardt & Jonathan Heiss)
Now that we have a basic understanding of how zk proofs are implemented, what conditions are needed to verify computations using ZK proofs?
- First, we need to choose a proof primitive; the ideal proof primitive should have low proof generation costs, low memory requirements, and be easy to verify.
- Second, select a zk circuit designed to generate proofs for the aforementioned primitive through computation.
- Finally, compute the given function with the provided inputs in a certain computing system/network and produce the output.
The Developer's Dilemma - The Proof Efficiency Conundrum
Another point worth mentioning is that the barrier to building circuits is still quite high. It is not easy for developers to learn Solidity, and now requiring developers to learn Circom or other specific programming languages (like Cairo) to build zk-apps seems like an unattainable task.
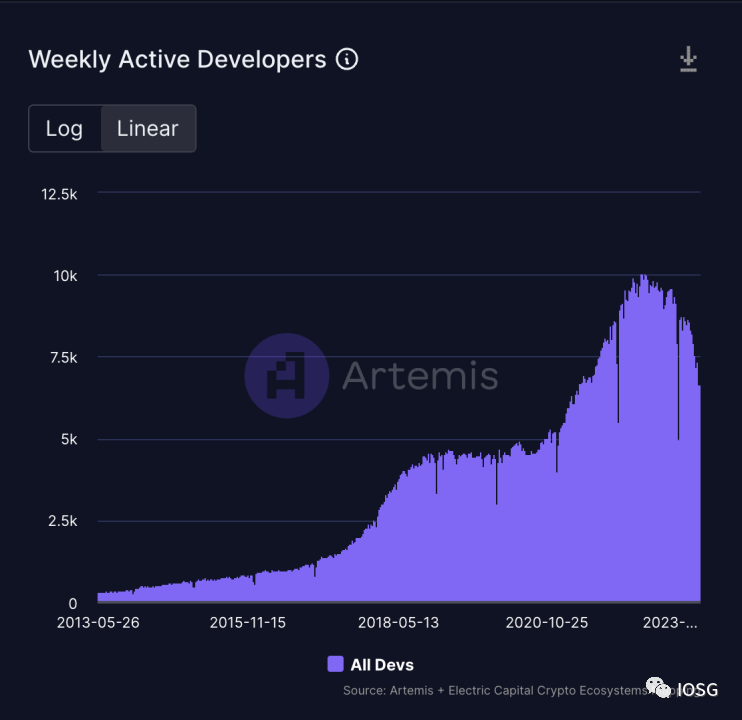
(Source: https://app.artemis.xyz/developers)
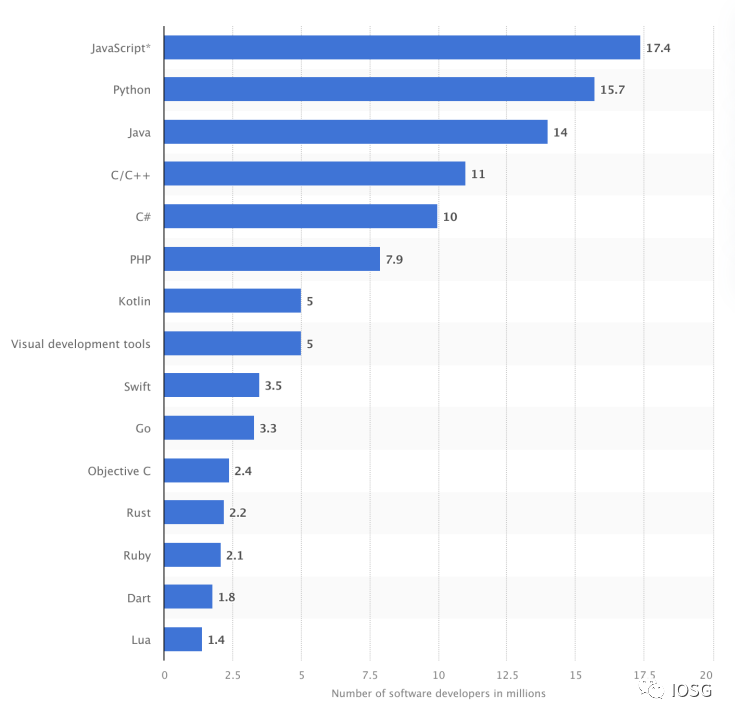
(Source: https://www.statista.com/statistics/1241923/worldwide-software-developer-programming-language-communities)
As the statistics above show, transforming the Web3 environment to be more developer-friendly seems more sustainable than introducing developers to a new Web3 development environment.
If ZK is the future of Web3, and Web3 applications need to leverage existing developer skills to build, then zk circuits need to be designed to support computations that generate proofs executed by algorithms written in languages like JavaScript or Rust.
Such solutions do exist, and I think of two teams: RiscZero and Lurk Labs. Both teams share a very similar vision, allowing developers to build zk-apps without going through a steep learning curve.
Lurk Labs is still in its early stages, but the team has been working on this project for a long time. They focus on generating Nova proofs through general circuits. Nova proofs were proposed by Abhiram Kothapalli from Carnegie Mellon University, Srinath Setty from Microsoft Research, and Ioanna Tziallae from New York University. Compared to other SNARK systems, Nova proofs have a special advantage in performing Incremental Verifiable Computation (IVC). Incremental Verifiable Computation (IVC) is a concept in computer science and cryptography aimed at verifying computations without having to recompute the entire computation from scratch. When computation times are long and complex, proofs need to be optimized for IVC.
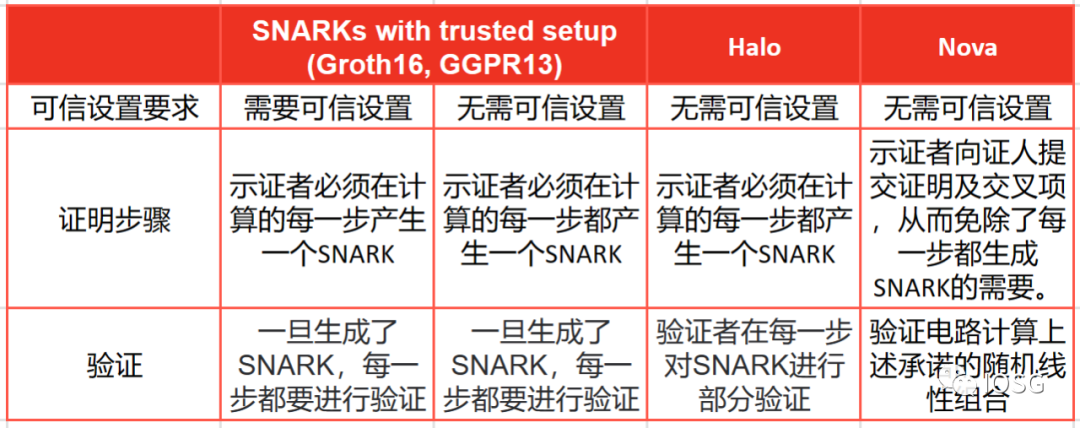
(Source: IOSG Ventures)
Nova proofs are not "plug-and-play" like other proof systems; Nova is merely a folding technique, and developers still need a proof system to generate proofs. This is why Lurk Labs built Lurk Lang, which is a LISP implementation. Since LISP is a lower-level language, it makes generating proofs on general circuits easy and can also be easily translated into JavaScript, which will help Lurk Labs gain support from 17.4 million JavaScript developers. It also supports translations for other general languages like Python.
In summary, Nova proofs seem to be a great primitive proof system. While their downside is that the size of the proof increases linearly with the size of the computation, on the other hand, Nova proofs have further compression potential.
The size of STARK proofs does not increase with the amount of computation, making it more suitable for verifying very large computations. To further improve the developer experience, they also launched the Bonsai network, a distributed computing network validated by proofs generated by RiscZero. Here is a simple schematic representing how RiscZero's Bonsai network works.
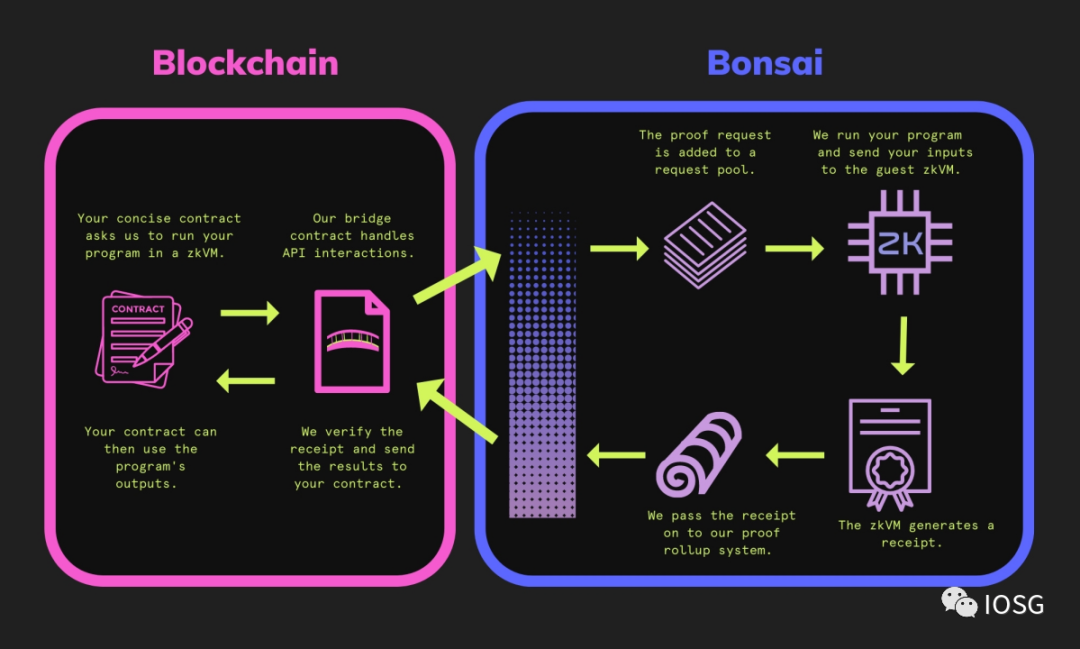
(Source: https://dev.bonsai.xyz/)
The beauty of the Bonsai network design is that computation can be initialized, verified, and output all on-chain. All of this sounds utopian, but STARK proofs also bring issues—verification costs are too high.
Nova proofs seem very suitable for repetitive computations (its folding scheme is cost-effective) and small computations, which may make Lurk a great solution for ML inference verification.
Who Are the Winners?


(Source: IOSG Ventures)
Some zk-SNARK systems require a trusted setup process during the initial setup phase to generate a set of initial parameters. The trust assumption here is that the trusted setup is executed honestly, without any malicious behavior or tampering. If attacked, it could lead to the creation of invalid proofs.
STARK proofs assume the security of low-degree tests for verifying low-degree properties of polynomials. They also assume that hash functions behave like random oracles.
The correct implementation of both systems is also a security assumption.
SMPC networks rely on the following points:
- SMPC participants can include "honest but curious" participants who may attempt to access any underlying information by communicating with other nodes.
- The security of the SMPC network relies on the assumption that participants correctly execute the protocol and do not intentionally introduce errors or malicious behavior.
- Certain SMPC protocols may require a trusted setup phase to generate cryptographic parameters or initial values. The trust assumption here is that the trusted setup is executed honestly.
- Similar to the SMPC network, the security assumptions remain the same, but due to the existence of OTM (Off-The-Grid Multi-party Computation), there are no "honest but curious" participants.
OTM is a multi-party computation protocol designed to protect participants' privacy. It achieves privacy protection by ensuring that participants do not publicly disclose their input data during computation. Therefore, "honest but curious" participants do not exist, as they cannot attempt to access underlying information by communicating with other nodes.
Is there a clear winner? We do not know. But each approach has its own advantages. While NMC appears to be a clear upgrade over SMPC, the network has not yet gone live and has not been tested in real-world scenarios.
The benefit of using ZK verifiable computation is that it is secure and privacy-preserving, but it lacks built-in secret sharing capabilities. The asymmetry between proof generation and verification makes it an ideal model for verifiable outsourced computation. If the system uses purely zk verifiable computation, the computer (or single node) must be very powerful to perform a large amount of computation. To enable load sharing and balancing while protecting privacy, secret sharing must be present. In this case, systems like SMPC or NMC can be combined with zk generators like Lurk or RiscZero to create a robust distributed verifiable outsourced computing infrastructure.
Today's MPC/SMPC networks are centralized, which is particularly important. The largest MPC provider currently is Sharemind, and the ZK verification layer on top of it can prove useful. The economic model of decentralized MPC networks has yet to be proven. Theoretically, the NMC model is an upgrade of the MPC system, but we have not yet seen its success.
In the race for ZK proof schemes, there may not be a winner-takes-all situation. Each proof method is optimized for specific types of computations, and there is no one-size-fits-all model. There are many types of computational tasks, and it also depends on the trade-offs developers make on each proof system. I believe that both STARK-based systems and SNARK-based systems, along with their future optimizations, have a place in the future of ZK.
 Risk warning
Risk warning Risk warning
Risk warning