ZKVMの生存の道、派閥争いを詳しく解説した記事

 最も直接な拡張に加えて、より興味深いユースケースが実現可能になります。例えば、ゼロ知識機械学習やデータ分析などです。Cairoのような特定のZK言語と比較して、Rust/C++の機能はより汎用的で強力であり、より多くのweb2のユースケースがRisc0 VM上で動作します。
最も直接な拡張に加えて、より興味深いユースケースが実現可能になります。例えば、ゼロ知識機械学習やデータ分析などです。Cairoのような特定のZK言語と比較して、Rust/C++の機能はより汎用的で強力であり、より多くのweb2のユースケースがRisc0 VM上で動作します。著者:Bryan, IOSG Ventures
目次
ZKP証明システムの回路実装 - 回路ベース(circuit-based) VS 仮想マシンベース(vm-based)
ZKVMの設計原則
STARKベースのVM間の比較
なぜRisc0が興奮を呼ぶのか
前書き:
2022年のrollupに関する主要な議論の焦点はZkEVMに集中しているようですが、ZkVMも別のスケーリング手段であることを忘れてはいけません。ZkEVMが本記事の焦点ではありませんが、ZkVMとZkEVMの間のいくつかの次元の違いを振り返る価値があります。
1. 互換性:どちらもスケーリングですが、焦点が異なります。ZkEVMは既存のEVMとの互換性を直接実現することに重点を置いており、ZkVMは完全なスケーリングを実現することを目指しています。つまり、dappのロジックとパフォーマンスを最適化し、互換性は最優先事項ではありません。基盤が整えば、EVM互換も実現可能です。
2.性能:両者には予測可能な性能面でのボトルネックがあります。ZkEVMの主なボトルネックは、EVMとの互換性に伴う余分なコストです。ZkVMのボトルネックは、命令セットISAを導入したため、最終的な出力の制約がより複雑になることです。
3.開発者体験: Type II ZkEVM(Scroll、Taikoなど)はEVMバイトコードの互換性を重視しています。言い換えれば、バイトコードレベルおよびそれ以上のEVMコードはZkEVMを通じて対応するゼロ知識証明を生成できます。ZkVMには2つの方向性があります。一つは独自のDSL(Cairoなど)を作成すること、もう一つはC++/Rustのような既存の成熟した言語との互換性を目指すこと(Risc0など)。将来的にはネイティブのSolidity Ethereum開発者が無コストでZkEVMに移行でき、より強力なアプリケーションはZkVM上で動作することが期待されます。

多くの人がこの図を覚えているでしょう。CairoVMがZkEVM派閥の争いから離れている本質的な理由は設計思想の違いです。
ZkVMについて議論する前に、まず考えるべきはブロックチェーンにおけるZK証明システムの実現方法です。大まかに言えば、回路を実現する方法は2つあります - 回路ベースのシステム(circuit based)と仮想マシンベースのシステム(vm-based)です。
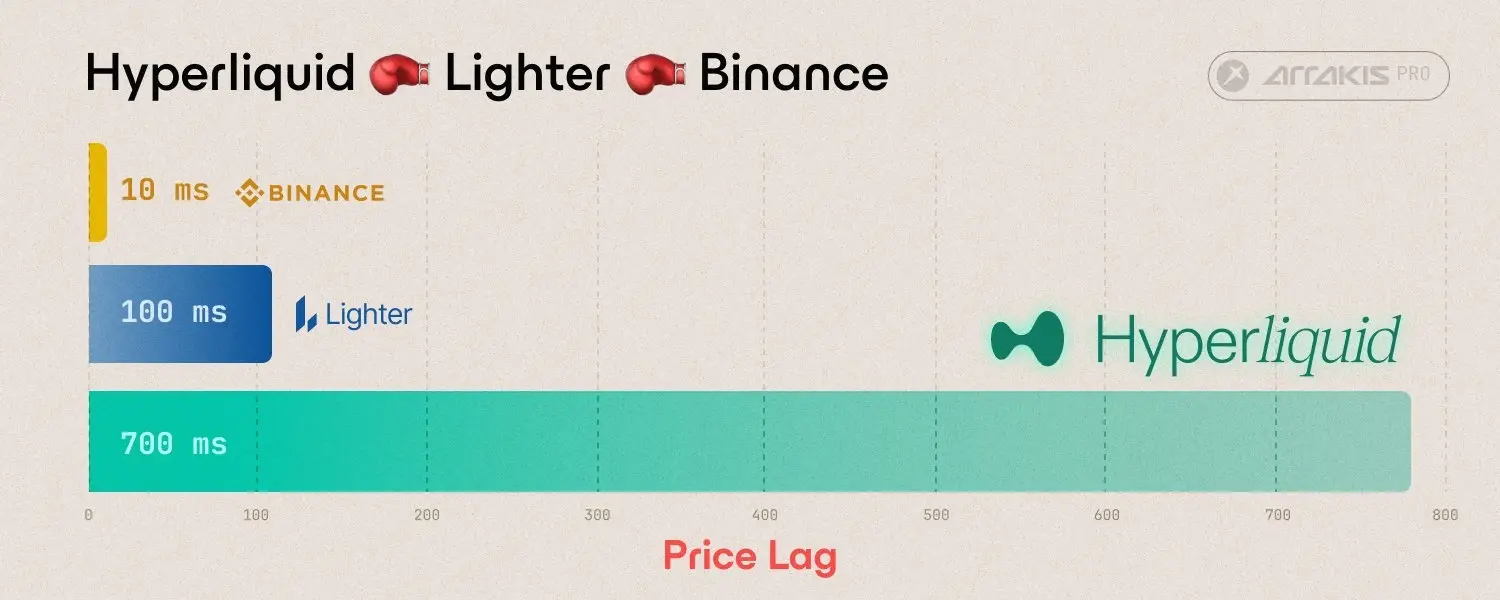
まず、回路ベースのシステムの機能はプログラム(program)を直接制約条件(constraints)に変換し、証明システム(proving system)に送信することです。仮想マシンベースのシステムは、命令セット(ISA)を介してプログラムを実行し、その過程で実行トレース(execution trace)を生成します。この実行トレースは後に制約条件にマッピングされ、証明システムに送信されます。
回路ベースのシステムでは、プログラムの計算は実行プログラムを実行する各マシン(machine)によって制約されます。一方、仮想マシンベースのシステムでは、ISAが回路生成器(circuit generator)に埋め込まれ、プログラムの制約(constraints)を生成します。同時に、回路生成器には命令セット、実行周期、メモリなどの制限があります。仮想マシンは汎用性を提供し、条件が上記の制限内であれば、任意のマシンでプログラムを実行できます。
仮想マシン内でのzkpプログラムはおおよそ以下のプロセスを経ます:
長所と短所:
開発者(developer)の観点から見ると、回路ベースのシステムでの開発は、各制約条件のコストを深く理解する必要があります。しかし、仮想マシンプログラムを書く場合、回路は静的であり、開発者は命令(instructions)にもっと関心を持つ必要があります。
検証者(verifier)の観点から見ると、同じ純SNARKをバックエンドとして使用した場合、回路ベースのシステムと仮想マシンは回路の汎用性において大きな違いがあります。回路システムは各プログラムに異なる回路を生成しますが、仮想マシンは異なるプログラムに対して同じ回路を生成します。これは、rollup内で回路システムがL1上に複数の検証契約(verifier contract)を展開する必要があることを意味します。
アプリケーション(application)の観点から見ると、仮想マシンはメモリモデル(memory)を設計に組み込むことでアプリケーションのロジックをより複雑にし、回路システムを使用する目的はプログラムの性能を向上させることです。
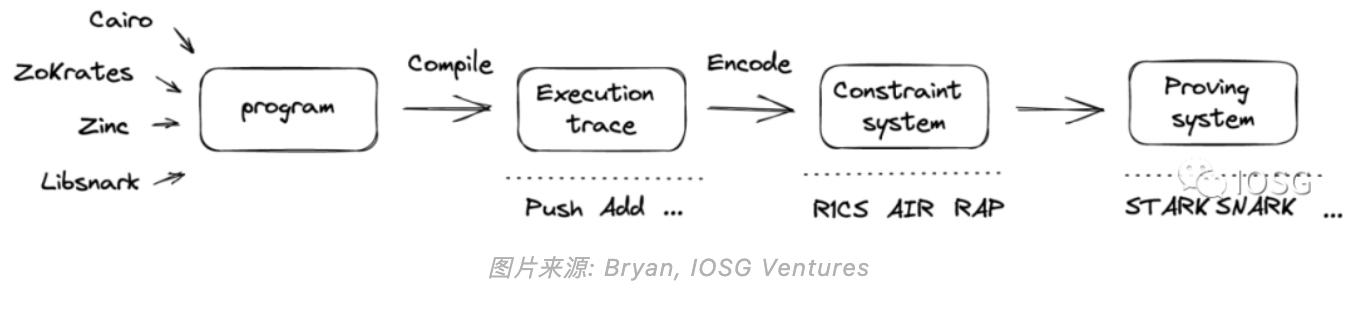
システムの複雑性(complexity)の観点から見ると、仮想マシンはメモリモデル、ホスト(host)とゲスト(guest)間の通信など、より多くの複雑性をシステムに取り入れています。それに対して、回路システムはよりシンプルです。 以下は現在のL1/L2における回路ベースと仮想マシンベースの異なるプロジェクトのプレビューです:
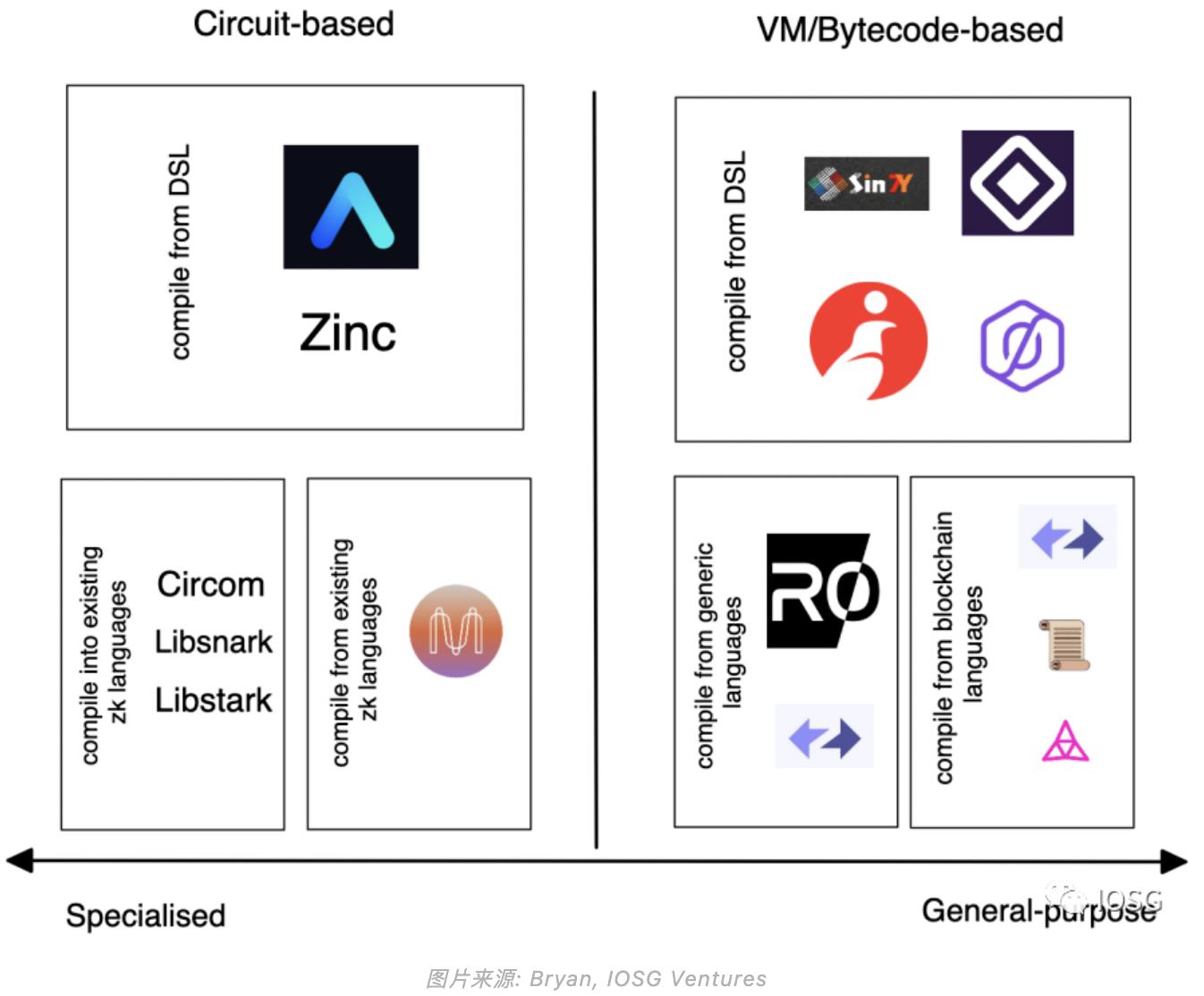
仮想マシンの設計原則
仮想マシンには2つの重要な設計原則があります。まず、プログラムが正しく実行されることを保証することです。言い換えれば、出力(output)(すなわち制約条件constraint)と入力(input)(すなわちプログラムprogram)が正しく一致する必要があります。一般的には、これはISA命令セットによって達成されます。次に、コンパイラ(compiler)が高級言語から適切な制約形式に変換する際に正しく機能することを保証します。 1. ISA命令セット
回路生成器の動作方法を規定します。主な責任は、命令(instructions)を正しく制約条件(constraint)にマッピングし、これらの制約条件がその後証明システム(proving system)に送信されることです。zkシステムで使用されるのはRISC(リデュースド・インストラクション・セット)です。ISAには2つの選択肢があります:
最初の選択肢はカスタムISA(custom ISA)を自作することです。これはCairoの設計に見られます。一般的には、以下の4種類の制約ロジックがあります。

カスタムISAの基本設計の重点は、制約条件を可能な限り少なくすることで、プログラムの実行と検証を迅速に行えるようにすることです。
2つ目は既存のISA(existing ISA)を利用することです。これはRisc0の設計に採用されています。 簡潔な実行時間を目指すだけでなく、既存のISA(Risc-Vなど)はフロントエンド言語(front-end language)やバックエンドハードウェア(backend hardware)に対しても追加の利点を提供します。1つの(解決が待たれる可能性のある)問題は、既存のISAが検証時間において遅れをとるかもしれないことです(検証時間はRisc-Vの主要な設計追求ではありません)。
2. コンパイラ(Compiler)
一般的に、コンパイラはプログラミング言語を段階的に機械コードに翻訳します。ZKの環境下では、C、C++、Rustなどの高級言語を制約システム(R1CS、QAP、AIRなど)の低級コード表現にコンパイルすることを指します。2つの方法があります。
既存のzk回路表現(existing circuit representations)に基づくコンパイラを設計することです。たとえば、ZKでは、回路の表現形式はBellmanのような直接呼び出し可能なライブラリ(library)やCircomのような低級言語から始まります。異なる表現形式を統合するために、Zokratesのようなコンパイラ(自身もDSLです)は、任意のより低級な表現形式にコンパイルできる抽象層を提供することを目指しています。
(既存の)コンパイラ基盤(compiler infrastructure)に基づいて構築することです。基本的な論理は、複数のフロントエンドとバックエンドに対する中間表現形式(intermediate representation)を利用することです。
Risc0のコンパイラはmulti-level intermediate representation(MLIR)に基づいており、複数のIR(LLVMに似ています)を生成できます。異なるIRは開発者に柔軟性を提供します。なぜなら、異なるIRにはそれぞれの設計重点があり、その中にはハードウェアに特化した最適化も含まれているため、開発者は自分の意向に応じて選択できます。同様の考え方はGCCを使用したvnTinyRAMやTinyRAMにも見られます。ZkSyncもコンパイラ基盤を利用した別の例です。
さらに、CirCのようなzk向けのコンパイラ基盤もあり、LLVMのいくつかの設計理念を借用しています。 上記の2つの最も重要な設計ステップに加えて、いくつかの他の考慮事項があります:
1. システムの安全性(security)と検証コスト(verifier cost)のトレードオフ
システムで使用されるビット数が多いほど(つまり安全性が高いほど)、検証コストが高くなります。安全性は鍵生成器(たとえばSNARKでは楕円曲線を表します)に反映されます。
2. フロントエンドとバックエンドの互換性(compatibility)
互換性は回路の中間表現(intermediate representation)の有効性に依存します。IRは正確性(プログラムの出力が入力と一致するか + 出力が証明システムに適合するか)と柔軟性(複数のフロントエンドとバックエンドをサポート)との間でバランスを取る必要があります。IRが最初にR1CSのような低次(low-degree)制約システムを解決するために設計された場合、他のより高次(high-degree)の制約システム(AIRなど)との互換性は難しくなります。
3. 効率を高めるために手作り(hand-crafted)の回路が必要
汎用モデル(general purpose)の欠点は、複雑な命令を必要としない単純な操作に対して効率が低いことです。 以前の理論を簡単に説明します。
Pinocchioプロトコル以前: 検証可能な計算を実現しましたが、検証時間が非常に遅かった。
Pinocchioプロトコル: 検証可能性と検証成功率の観点で理論的な実現可能性を提供しました(つまり、検証の時間はプログラムの実行時間より短い)、これは回路ベースのシステムです。
TinyRAMプロトコル: Pinocchioプロトコルに対して、TinyRAMは仮想マシンに近く、ISAを導入し、メモリアクセス(RAM)、制御フロー(control flow)などのいくつかの制限を克服しました。
vnTinyRAMプロトコル: 鍵生成(key generation)が各プログラムに依存しないことを実現し、追加の汎用性を提供しました。拡張回路生成器は、より大きなプログラムを処理できるようになります。
上記のモデルはすべてSNARKをバックエンド証明システムとして使用していますが、特に仮想マシンを扱う際には、STARKとPlonkがより適切なバックエンドであるようです。根本的には、その制約システムがCPUのようなロジックの実現に適しているからです。
次に、 本文では3つのSTARKベースの仮想マシン - Risc0, MidenVM, CairoVMを紹介します。簡単に言えば、これらはすべてSTARKを証明システムとして使用していますが、それぞれにいくつかの違いがあります:
- - Risc0はRisc-Vを利用して命令セットの簡潔性を実現しています。R0はMLIRでコンパイルされ、これはLLVM-IRの一種であり、Rust、C++などの既存の汎用プログラミング言語をサポートすることを目的としています。Risc-Vにはハードウェアに優しいという追加の利点もあります。
- - Midenの目標はEthereum仮想マシン(EVM)との互換性を持つことで、本質的にはEVMのrollupです。Midenは現在独自のプログラミング言語を持っていますが、将来的にはMoveをサポートすることにも取り組んでいます。
- - Cairo VMはStarkwareによって開発されました。これらの3つのシステムが使用するSTARK証明システムはEli Ben-Sassonによって発明され、現在Starkwareの社長です。
それらの違いをより深く理解しましょう:
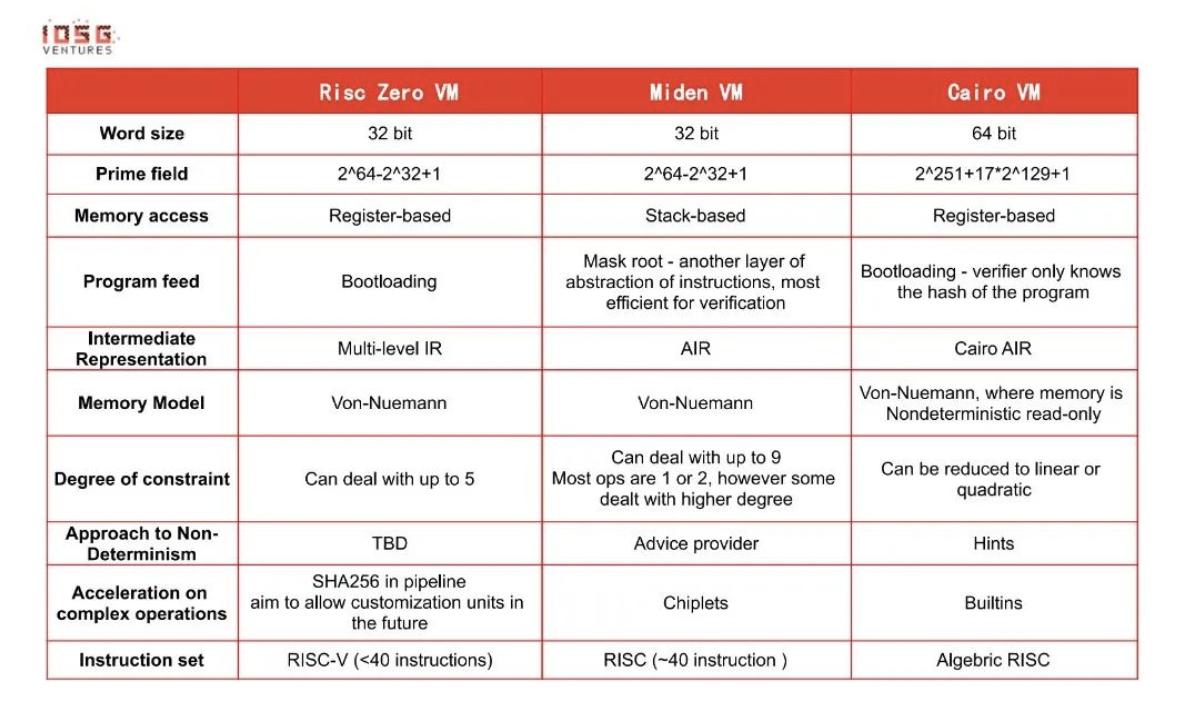
* 上記の表をどう読むか?いくつかの注釈…
●Word size(ワードサイズ) - これらの仮想マシンが基づく制約システムはAIRであり、その機能はCPUアーキテクチャに似ています。したがって、CPUのワードサイズ(32/64ビット)を選択するのが適切です。
●Memory access(メモリアクセス)- Risc0がレジスタ(register)を使用する理由は、Risc-V命令セットがレジスタベースであるためです。Midenは主にスタック(stack)を使用してデータを保存します。AIRの機能はスタックに似ています。CairoVMは一般的なレジスタ(general-purpose register)を使用していません。なぜなら、Cairoモデルにおけるメモリアクセス(main memory)のコストが低いためです。
●Program feed(プログラム実行)- 異なる方法にはトレードオフがあります。たとえば、mast root方法は命令を処理する際にデコードが必要なため、実行ステップが多いプログラムでは証明者のコストが高くなります。Bootloading方法は、プライバシーを保持しつつ、証明者のコストと検証者のコストの間でバランスを取ろうとします。
●Non-determinism(非決定性)- 非決定性はNP完全問題の重要な特性です。非決定性を利用することで、過去の実行を迅速に検証できます。逆に言えば、より多くの制約条件が追加されるため、検証においていくつかの妥協が生じます。
●A cceleration on complex operations(複雑な操作の加速)- 一部の計算はCPU上で非常に遅く実行されます。たとえば、ビット操作(XORやAND)、ハッシュプログラム(ECDSAなど)、範囲チェック(range-check)などです。これらはほとんどがブロックチェーン/暗号技術のネイティブな計算ですが、CPUのネイティブな計算ではありません(ビット操作を除く)。これらの計算をDSLを通じて直接実現すると、証明の周期(cycle)が尽きる可能性が高くなります。
●P ermutation/multiset(排列/多重集合) - 大多数のzkVMで広く使用されており、2つの目的があります - 1. 完全な実行トレース(execution trace)を保存することによって検証者のコストを削減すること 2. 検証者が完全な実行トレースを知っていることを証明すること。 記事の最後に、筆者はRisc0の現在の発展とその興奮を呼ぶ理由について話したいと思います。
R0の現在の発展:
a. 自社開発の「Zirgen」コンパイラ基盤が開発中です。Zirgenといくつかの既存のzk専用コンパイラの性能を比較するのは興味深いでしょう。
b. フィールド拡張のような非常に興味深い革新があり、より堅固な安全パラメータを実現し、より大きな整数での操作を可能にします。
c. ZKハードウェアとZKソフトウェア企業間の統合における課題を目の当たりにしました。Risc0はハードウェアの開発をより良くするためにハードウェア抽象層を使用しています。
d. まだ進行中の作業です!開発中です!
- 手作りの回路(hand-crafted circuits)をサポートし、さまざまなハッシュアルゴリズムをサポートします。現在、専用のSHA256回路が実装されていますが、すべてのニーズを満たすことはできません。筆者は、最適化する回路の具体的な選択はRisc0が提供するユースケース(use case)に依存すると信じています。SHA256は非常に良い出発点です。一方で、ZKVMの位置付けは柔軟性を提供します。たとえば、彼らが望まない限り、Keccakを気にする必要はありません :)
- 再帰(recursion):これは大きな話題であり、筆者はこの報告書で深く掘り下げることを避けたいと思います。知っておくべきことは、Risc0がより複雑なユースケース/プログラムをサポートする傾向があるため、再帰の必要性が高まっていることです。再帰をさらにサポートするために、彼らは現在ハードウェア側でのGPU加速ソリューションを研究しています。
- 非決定性(non-determinism)の処理:これはZKVMが対処しなければならない特性であり、従来の仮想マシンにはこの問題はありません。非決定性は仮想マシンの実行を速くするのに役立ちます。MLIRは従来の仮想マシンの問題を処理するのが得意ですが、Risc0が非決定性をZKVMシステム設計にどのように組み込むかは期待されます。
私が興奮する理由:
a. シンプルで検証可能!
分散システムにおいて、PoWは高い冗長性を必要とします。なぜなら、人々は他者を信頼しないため、合意を得るために同じ計算を繰り返し実行する必要があるからです。しかし、ゼロ知識証明を利用することで、状態の実現は1+1=2に同意するのと同じくらい簡単であるべきです。
b. より多くの実用的なユースケース:
最も直接的なスケーリングを超えて、ゼロ知識機械学習、データ分析などのより興味深いユースケースが実現可能になります。Cairoのような特定のZK言語に比べて、Rust/C++の機能はより汎用的で強力であり、より多くのweb2のユースケースがRisc0 VM上で動作します。
c. より包括的で成熟した開発者コミュニティ:
STARKとブロックチェーンに興味のある開発者は、DSLを再学習する必要はなく、Rust/C++を使用するだけで済みます。
 リスク警告
リスク警告 リスク警告
リスク警告