IOSG:なぜ私たちはゼロ知識証明のハードウェアアクセラレーションに期待しているのか?

 現在の解決策は、次の2つの問題に直面せざるを得ません。1. 中央集権化、つまりユーザーの情報が依然として検閲されるリスクがあること。2. 検証可能なデータ形式が単一であること。オフチェーンデータは多様で非標準化されているため、検証可能なデータ形式は大量のクレンジング/フィルタリングを経る必要があり、それでもなお形式が単一です。
現在の解決策は、次の2つの問題に直面せざるを得ません。1. 中央集権化、つまりユーザーの情報が依然として検閲されるリスクがあること。2. 検証可能なデータ形式が単一であること。オフチェーンデータは多様で非標準化されているため、検証可能なデータ形式は大量のクレンジング/フィルタリングを経る必要があり、それでもなお形式が単一です。著者:Bryan,IOSG Ventures
この記事では、ZKPの拡張ソリューションとしての発展状況について主に議論し、理論的な観点から証明生成プロセスで最適化が必要な主要な次元を説明し、異なる拡張ソリューションが加速のニーズにどのように関連しているかを掘り下げます。その後、ハードウェアソリューションに焦点を当て、zkハードウェアアクセラレーション分野におけるムーアの法則を展望します。最後に、ハードウェアzkアクセラレーション分野のいくつかの機会と現状について、文末で述べます。まず、証明速度に影響を与える主な次元は3つあります:証明システム、待証明回路の規模、アルゴリズムのソフトウェアおよびハードウェアの最適化です。
証明システムに関しては、楕円曲線(EC)を使用するアルゴリズム、つまり市場で主流のGroth 16(Zcash)、Galo2(Scroll)、Plonk(Aztec、Zksync)などのzk-snarkアルゴリズムは、多項式コミットメントの生成プロセスで関与する大数点乗算(MSM)において、現在、時間がかかる(計算力の要求が高い)ボトルネックがあります。FRIベースのアルゴリズム、例えばZK-Starkは、多項式コミットメントの生成方法がハッシュ関数であり、ECを関与させないため、MSM計算は関与しません。
証明システムは基盤であり、待証明回路の規模もハードウェア最適化のニーズの一つです。最近議論が盛んなZKEVMは、イーサリアムとの互換性の程度が異なるため、回路の複雑さが異なります。例えば、Zksync/Starkwareは、ネイティブイーサリアムとは異なる仮想マシンを構築し、zk処理に適さないイーサリアムのネイティブな低レベルコードを回避し、回路の複雑さを縮小しました。一方、Scroll/Hermezのように、最も下層から互換性のあるzkevmの回路は自然により複雑になります。
理解しやすい比喩として、回路の複雑性はバスの座席数として理解できます。例えば、通常の日常では30人以下の乗客を運ぶ必要がある場合、30人の座席を選択したバスはZksync/StarkWareであり、年間の特定の日には特に多くの乗客がいるため、一般的なバスでは収容できないことがあります。そのため、より多くの座席を設計したバス(Scroll)も存在します。しかし、これらの日は比較的少ないため、通常は多くの空席が生じることになります。
ハードウェアアクセラレーションは、これらのより複雑な回路設計にとってより緊急ですが、これはよりSpectrumの問題です。ZKEVMにも同様に利点と欠点があります。
異なる証明システムの最適化ニーズ/重点:
基本:
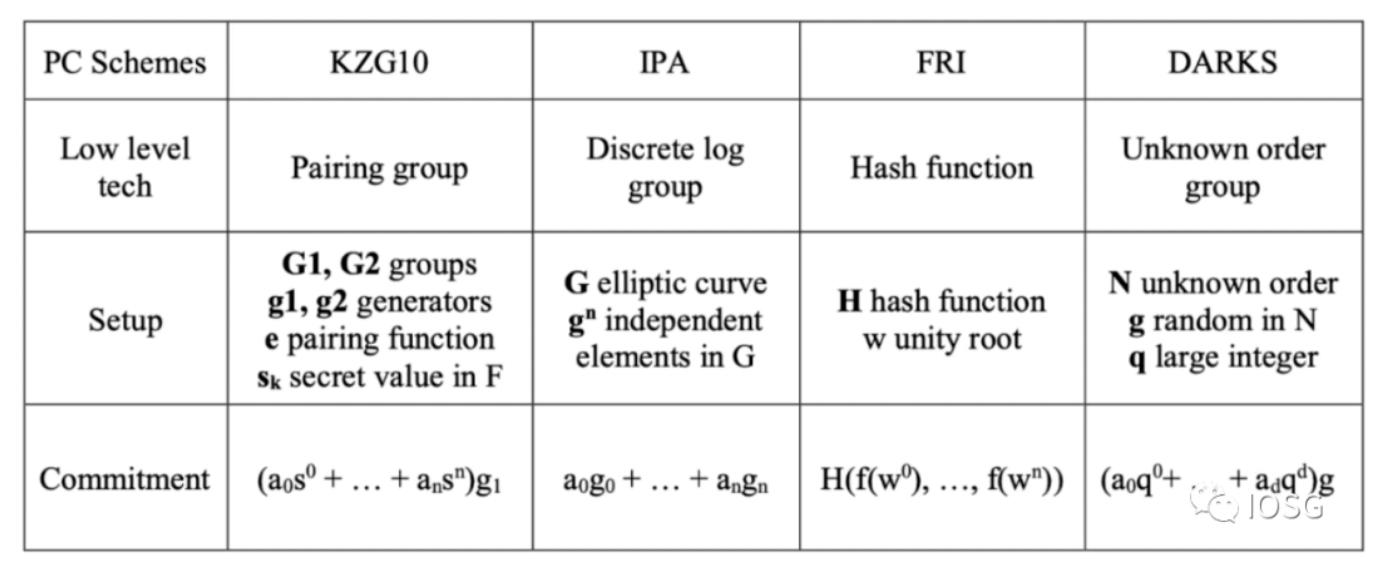
待証明の事象が回路(R1CS/QAPなど)を通過すると、一組のスカラーとベクトルが得られ、その後、多項式やinner product argument(groth16)などの他の代数形式を生成するために使用されます。この多項式は依然として冗長であり、直接証明を生成すると、証明のサイズや検証時の時間が非常に大きくなります。したがって、この多項式をさらに簡素化する必要があります。ここでの最適化手法は多項式コミットメントと呼ばれ、多項式の特別なハッシュ値として理解できます。代数に基づく多項式コミットメントにはKZG、IPA、DARKがあり、これらはすべて楕円曲線を使用してコミットメントを生成します。
FRIはハッシュ関数を主要なコミットメント生成手段としています。多項式コミットメントの選択は主にいくつかの点に基づいています - セキュリティ、パフォーマンス。ここでのセキュリティは、セットアップ段階で考慮されます。生成された秘密に使用されるランダム性が公開されている場合、例えばFRIの場合、このセットアップは透明であると言います。秘密に使用されるランダム性がプライベートであり、Proverが使用後に破棄する必要がある場合、このセットアップは信頼される必要があります。MPCはここで信頼が必要な手段の一つですが、実際のアプリケーションでは、ユーザーが一定のコストを負担する必要があることがわかりました。
上記のように、セキュリティ面で相対的に優れたFRIは、パフォーマンスが理想的ではありません。また、ペアリングフレンドリーな楕円曲線のパフォーマンスは比較的優れていますが、再帰を追加することを考慮すると、適切な曲線はあまり多くないため、かなりのオーバーヘッドが存在します。
 画像出典:https://hackernoon.com
画像出典:https://hackernoon.com
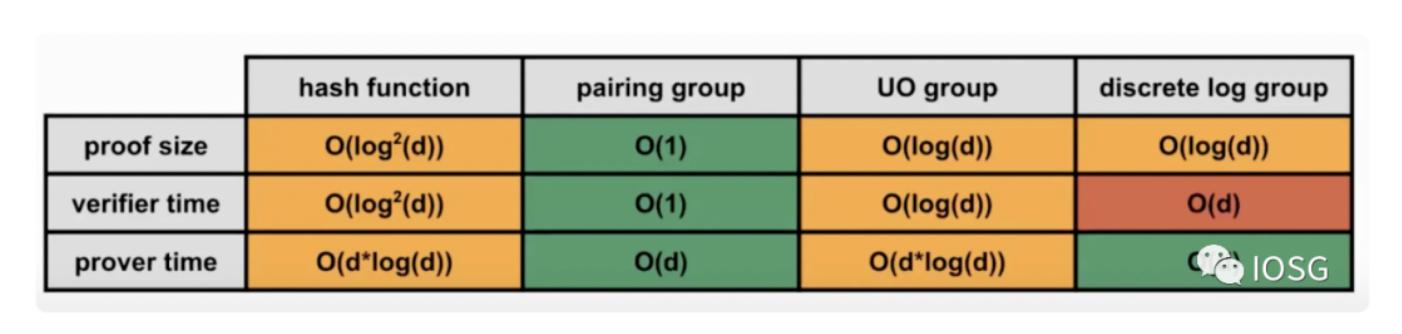 Justin Drake on Polynomial commitment, Part 1
Justin Drake on Polynomial commitment, Part 1
業界の現状:
現在、Plonk(matterlabs)またはUltra-Plonk(Scroll、PSE)に基づくものであれ、最終的な多項式コミットメントはKZGに基づいているため、Proverの大部分の作業は大量のFFT計算(多項式生成)とECC点乗算MSM計算(多項式コミットメント生成)に関与します。
純粋なplonkモードでは、コミットするポイントの数がそれほど多くないため、MSM計算がProve時間に占める割合は高くありません。そのため、FFTパフォーマンスの最適化は短期的に大きなパフォーマンス向上をもたらすことができます。しかし、UltraPlonk(halo2)フレームワークでは、カスタマーゲートが導入され、Prover段階で設計されたコミットのポイント数が増加し、MSM計算のパフォーマンス最適化も非常に重要になります。(現在、MSM計算はpippenger最適化の後でも、log(P(logB))が必要です(Bはexpの上界、pはMSMに参加するポイントの数です)。
現在の新世代Plonky2証明システムは、採用されている多項式コミットメントがKZGではなく、STARKシステムで一般的なFRIであるため、Plonky2のProverはMSMを考慮する必要がなく、理論的にはこのシステムのパフォーマンス向上はMSM関連のアルゴリズム最適化に依存しなくなります。Plonky2の著者であるMir(現在のPolygon Zero)は、このシステムを大いに推進しています。しかし、Plonky2が採用している数域Goldilocks Fieldは、楕円曲線関連のハッシュアルゴリズム関連の回路(例えばECDSA)を記述するにはあまり友好的ではないため、Goldilocks Fieldがマシンワード演算の面で明らかな利点を持っているにもかかわらず、MirとPSE/Scrollのどちらの方案がより良いかを判断するのは難しいです。
Plonk、Ultraplonk、Plonky2のProveアルゴリズムを総合的に考慮すると、ハードウェアアクセラレーションが必要なモジュールは、FFT、MSM、HASHの3つの方向に集中する可能性が高いです。
Proverのもう一つのボトルネックは、ウィットネスの生成です。通常、普通の非zk計算では大量の中間変数を省略しますが、ZK証明のプロセスでは、すべてのウィットネスを記録する必要があり、その後のFFT計算にも参加するため、効率的に並行してウィットネスを計算する方法もProverマイニング機器が潜在的に考慮すべき方向です。
ZKPの加速に関する試み:再帰的証明 - StarkNetのフラクタルL3概念は再帰的証明の概念に基づいており、Zksyncのフラクタルハイパースケーリング、Scrollにも類似の最適化があります。
再帰的zkSNARKの概念は、Proof Aの検証プロセスを証明し、別のProof Bを生成します。VerifierがBを受け入れる限り、Aも受け入れたことになります。再帰SNARKは、複数の証明を集約することもでき、例えばA1、A2、A3、A4の検証プロセスをBに集約することができます。再帰SNARKは、長い計算プロセスをいくつかのステップに分解することもでき、各ステップの計算証明S1は次のステップの計算証明で検証される必要があります。つまり、一歩計算し、一歩検証し、次のステップを計算することで、Verifierは最後のステップだけを検証すればよく、長さが不定の大きな回路を構築する難しさを回避できます。
理論的には、zkSNARKはすべて再帰をサポートしており、一部のzkSNARK方案はVerifierを回路で実装できますが、他のzkSNARKはVerifierアルゴリズムを回路化しやすい部分としにくい部分に分割する必要があります。後者は遅延集約検証の戦略を採用し、検証プロセスを最後のステップの検証プロセスに置きます。
L2の将来のアプリケーションにおいて、再帰の利点は、証明対象の事象の帰納を通じてコストや性能の要求をさらに低下させることができます。
第一のケース(アプリケーションに依存しない)は、異なる待証明の事象に対して、例えば一つは状態更新で、もう一つはマークルツリーであり、これら二つの待証明事象の証明は一つの証明に統合できますが、依然として二つの出力結果(それぞれ検証用の公開鍵)が存在します。
第二のケース(アプリケーション再帰)は、同類の待証明事象に対して、例えば二つとも状態更新であれば、これら二つの事象は証明生成前に集約され、出力結果は一つだけで、その結果は二回の更新を経た状態差分です。(Zksyncの方法も類似しており、ユーザーコストは状態差分にのみ責任を持ちます)
再帰的証明や以下で主に議論するハードウェアアクセラレーションの他にも、ZKPを加速する方法は他にもあり、例えばカスタムゲートやFFTの除去(OlaVMの理論基盤)などがありますが、この記事では篇幅の関係上、議論しません。
ハードウェアアクセラレーション
ハードウェアアクセラレーションは、暗号学において常に暗号学的証明を加速する一般的な手段であり、RSA(RSAの基礎となる数学的論理は楕円曲線と類似しており、複雑な大数演算を多く含みます)や、初期のzcash/filecoinのzk-snarkのGPUベースの最適化方法に対しても同様です。
ハードウェアの選択
イーサリアムのThe Mergeが発生した後、避けられないことに大量のGPU計算力の余剰が生じます(部分的にはイーサリアムのコンセンサス変更の影響を受け、GPU大手のNVIDIAの株価は年初から50%下落し、在庫の余剰も増加しています)。下の図はNVIDIAのGPUフラッグシップ製品RTX 3090の取引価格を示しており、買い手の力が比較的弱いことを示しています。
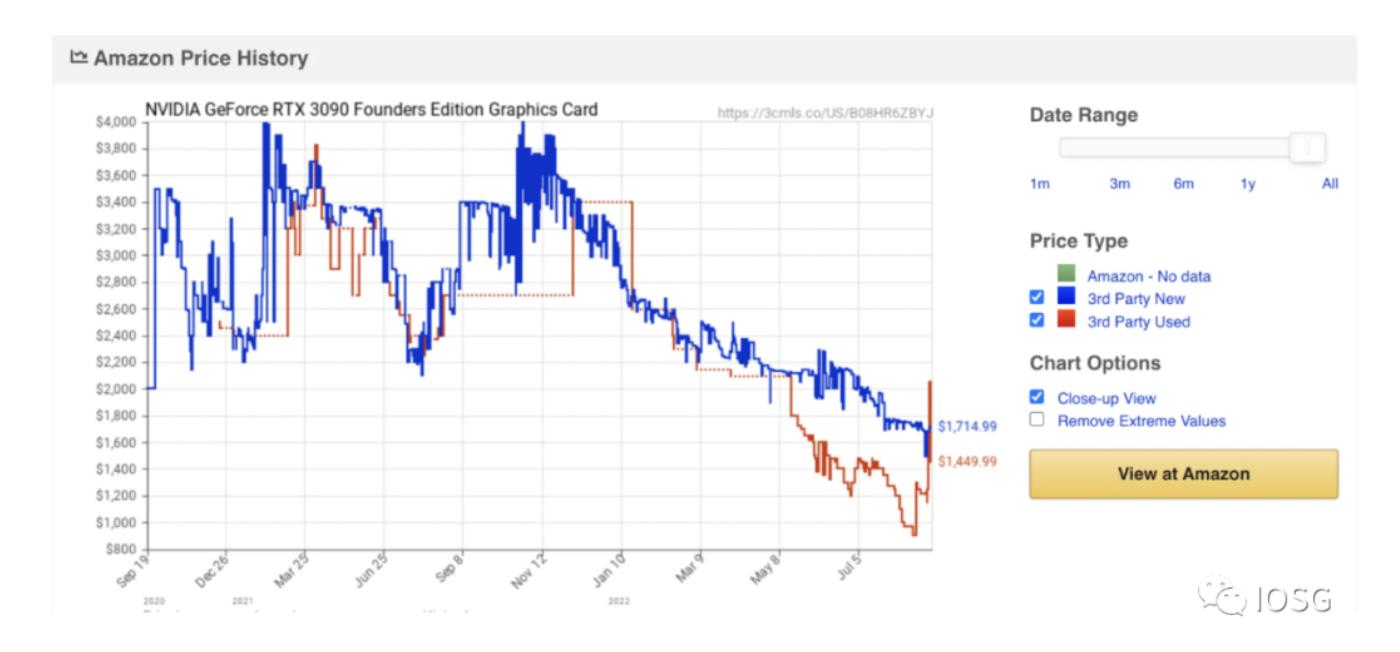
GPU価格が低迷し、大量のGPU計算力が遊休状態にある中で、自然な疑問は、GPUがzkを加速するための適切なハードウェアであるかどうかです。ハードウェア側には主に3つの選択肢があります:GPU/FPGA/ASIC。
FPGA vs GPU:
まずはまとめ:以下はtrapdoor-techによるGPU(Nvidia 3090を例に)とFPGA(Xilinx VU9Pを例に)に関するいくつかの次元でのまとめです。非常に重要な点は、GPUは性能(証明生成の速度)においてFPGAを上回り、FPGAはエネルギー消費において優位性を持つということです。
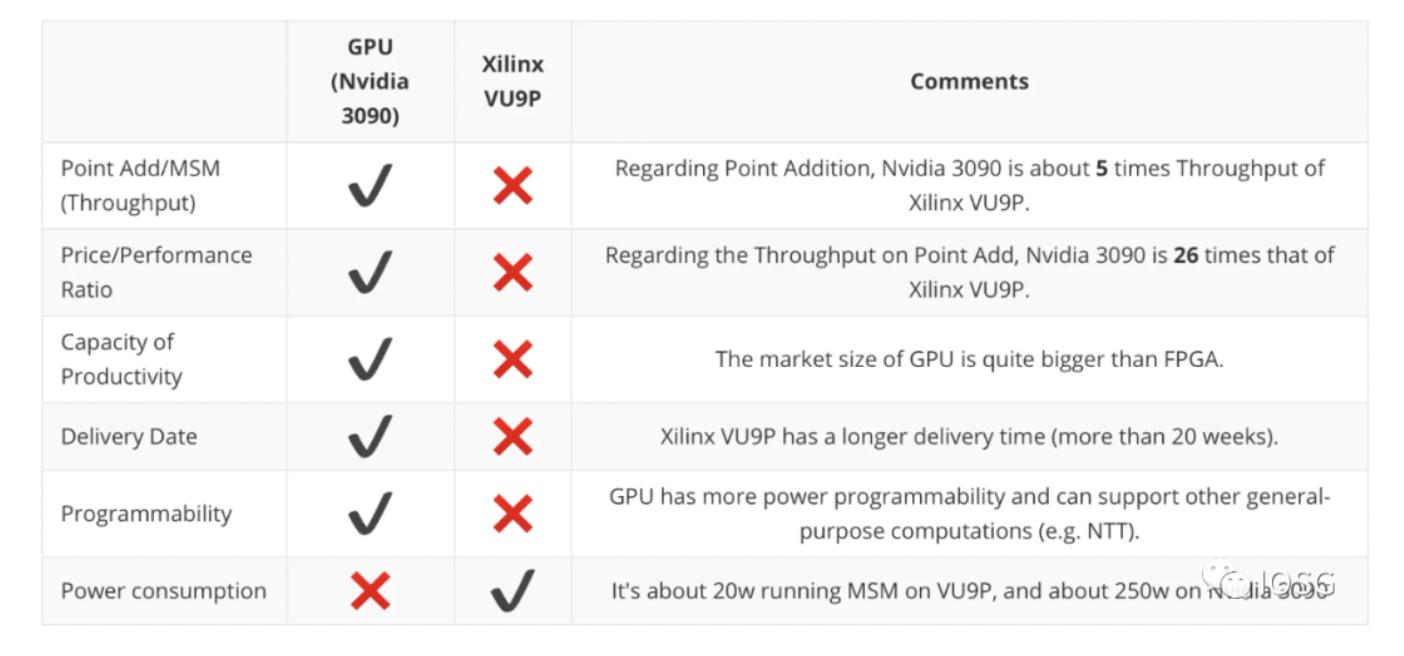
Ingoyamaからの具体的な実行結果:
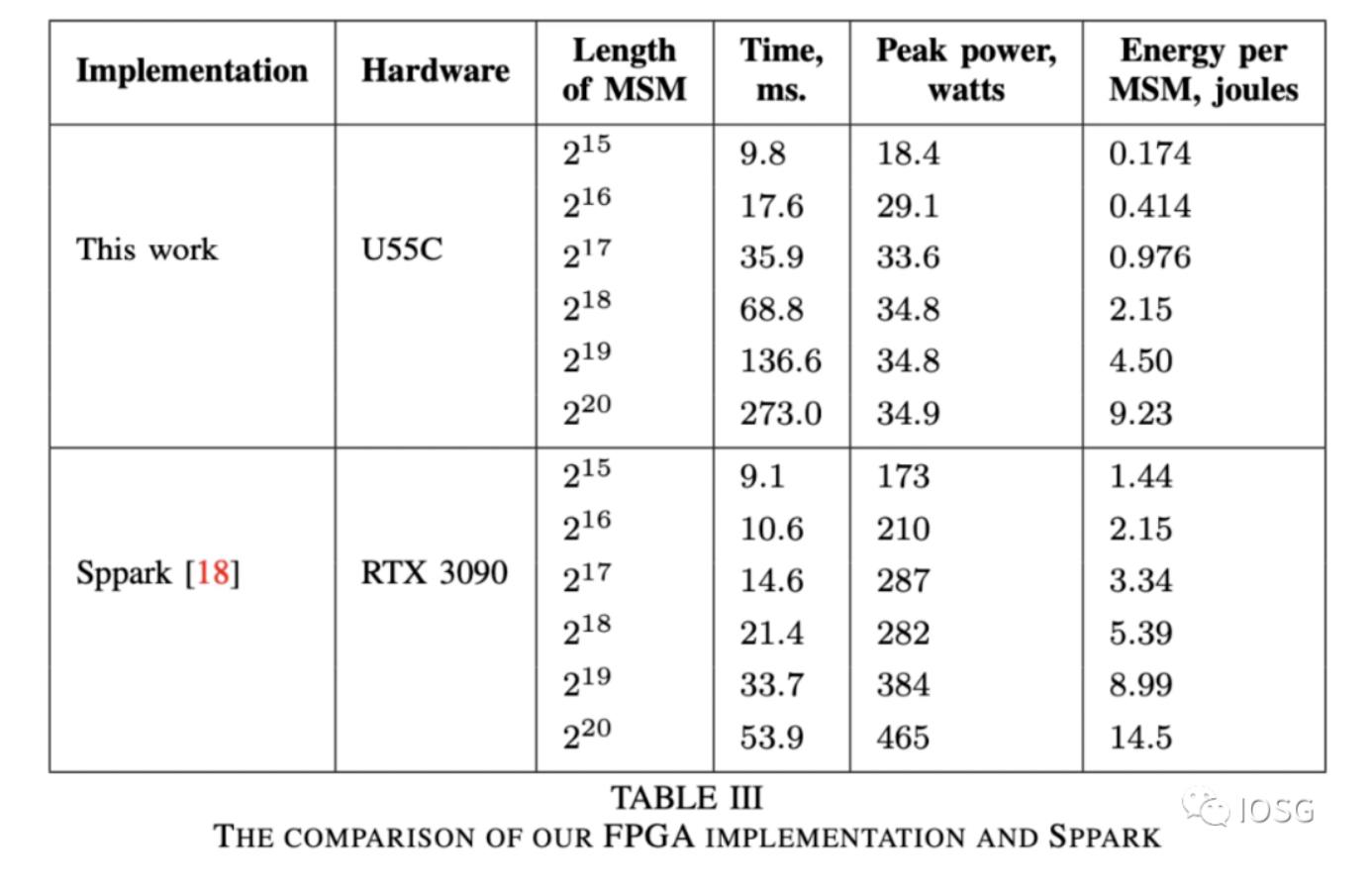
特にビット幅が高い(2^20)の演算において、GPUはFPGAの演算速度の5倍であり、消費電力も同時に高くなります。
一般のマイナーにとって、コストパフォーマンスもどのハードウェアを使用するかを判断する重要な要素です。U55C($4795)やVU9P($8394)と比較して、GPU(RTX 3090:$1860)の価格ははるかに高くなります。
理論的には、GPUは並列計算に適しており、FPGAはプログラム可能性を追求しますが、ゼロ知識証明生成の環境では、これらの利点は完璧には適用されません。例えば、GPUが適用する並列計算は大規模なグラフィック処理に対してであり、論理的にはMSMの処理方法に類似していますが、適用範囲(浮動小数点数)とzkpが対象とする特定の有限体とは一致しません。FPGAに関しては、プログラム可能性が複数のL2の存在するアプリケーションシナリオでは明確ではありません。L2のマイナー報酬が単一のL2の需要に結びついているため(powとは異なり)、細分化された競技場で「勝者がすべてを取る」状況が発生する可能性が低く、マイナーが頻繁にアルゴリズムを変更する必要がある可能性は高くありません。
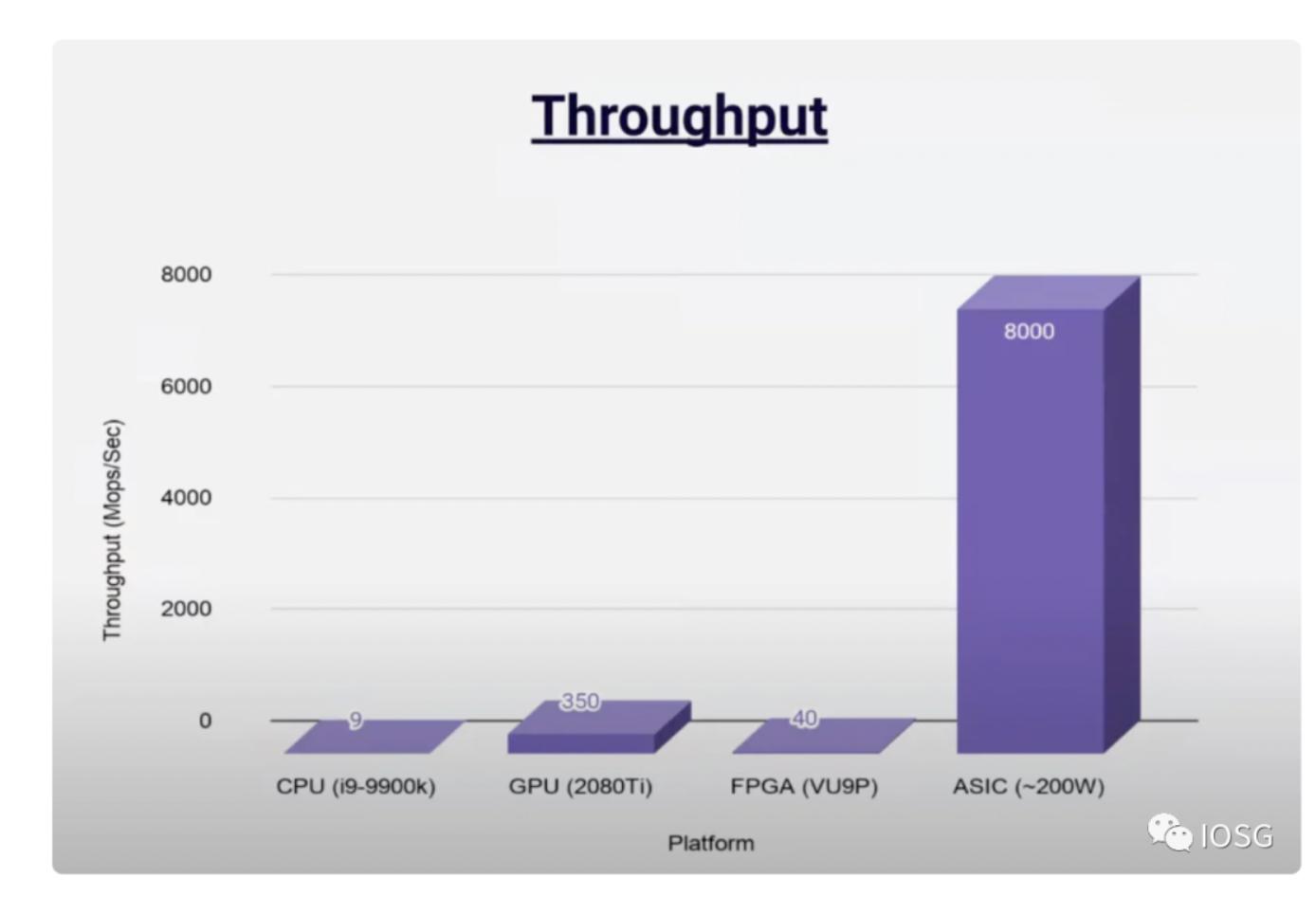 ASICは性能とコストのバランスが優れたソリューション(スループット、遅延などを含む)ですが、最良のソリューションであるかどうかは未だに結論が出ていません。存在する問題は:
ASICは性能とコストのバランスが優れたソリューション(スループット、遅延などを含む)ですが、最良のソリューションであるかどうかは未だに結論が出ていません。存在する問題は:
開発時間が長い - 完全なチップ設計からチップ生産のプロセスを経る必要があり、現在すでにチップが設計されていても、チップ生産は長く、資金がかかり、良品率も一定ではありません。代工リソースに関しては、TSMCとSamsungが最良のチップ代工工場であり、現在TSMCの注文は2年先まで埋まっており、ZKチップと競合する代工リソースはAIチップや電気自動車チップなど、Web2で早くからチップ設計が行われ、需要が証明された製品です。それに対してZKチップの需要は明確ではありません。
次に、チップ全体の性能と単一チップのサイズ、つまり一般的に言われる20nm、18nmは負の相関関係にあります。つまり、単一チップが小さくなるほど、チップが収容できるチップの数が増え、全体の性能が向上しますが、現在の高端チップ製造技術は独占されています(例えば、チップ製造で最も複雑なプロセスであるフォトリソグラフィ技術はオランダのASML社が独占しています)。中小型の代工工場(国内の中芯国際など)は、技術面でトップクラスに1〜2世代遅れているため、良品率やチップサイズの面で最良の代工工場に劣ります。これにより、ZKチップは次善の解決策を探るしかなく、需要が明確でない状況でコストを考慮して約28nmの非高端チップを選択することになります。
現在のASICソリューションは、FFTおよびMSMという2つの一般的なZK回路で計算力要求が比較的高い演算子を主に処理しており、特定のプロジェクトに対して設計されているわけではないため、具体的な実行効率は理論的に最高ではありません。例えば、現在ScrollのProverの論理回路は100%実現されておらず、当然それに対応するハードウェア回路も存在しません。また、ASICはアプリケーション固有であり、後続の調整をサポートしません。論理回路が変更された場合、例えばノードのクライアントがアップグレードする必要がある場合、互換性のあるソリューションが存在するかどうかも現在は不確かです。
同時に、人材不足もZKチップの業界の現状であり、暗号学とハードウェアを理解する人材は見つけるのが難しく、適切な候補者は深い数学的知識と多年的なハードウェア製品設計および保守経験を兼ね備えています。
結論 - proverの発展トレンドEigenDA
以上は、業界がZKPを加速するための考察と試みであり、最終的な意味はProverの運用のハードルがますます低くなることです。周期的に、Proverは大まかに以下の3つの段階を経る必要があります:
フェーズI:クラウドベースのProver
クラウドベースのProverは、第三者Prover(ユーザー/プロジェクト側ではない)の参入障壁を大幅に引き上げることができます。これはWeb2のAWS/Google Cloudに類似しています。ビジネスモデルの観点からは、プロジェクト側は一部の報酬を失いますが、分散化の物語から見ると、これは経済的および実行面でより多くの参加者を引き付ける方法です。クラウドコンピューティング/クラウドサービスはWeb2の既存の技術スタックであり、開発者が使用できる成熟した開発環境があり、クラウド特有の低いハードル/高い集団効果を発揮でき、短期的な証明のアウトソーシングの選択肢となります。
現在、Ingoyamaもこの分野での実現を進めています(最新のF1版はpipeMSMの基準速度の2倍に達しました)。しかし、これは依然として単一のProverが全体の証明を実行する方法であり、フェーズIIでは証明が分割可能な形式で存在し、参加者の数が増えることになります。
フェーズII:Proverマーケットプレイス
証明生成のプロセスには異なる演算が含まれており、ある演算は効率に偏りがあり、他の演算はコスト/エネルギー消費に要求があります。例えば、MSM計算は事前計算を含み、これは異なる事前計算のスカラー粒子をサポートするために一定のメモリを必要とします。すべてのスカラーが1台のコンピュータに存在する場合、そのコンピュータのメモリ要求は高くなりますが、異なるスカラーを複数のサーバーに保存すれば、その計算の速度が向上し、参加者の数も増加します。
マーケットプレイスは、上記のアウトソーシング計算に対するビジネスモデルの大胆な考察です。しかし、実際にはCrypto界にも前例があります - Chainlinkのオラクルサービスでは、異なるチェーン上の異なる取引ペアの価格を供給することもマーケットプレイスの形式で存在します。同時に、Aleoの創設者Howard Wuは、分散型台帳のゼロ知識証明生成方法論であるDIZKを共同執筆したことがあります。理論的には実行可能です。
話を戻すと、ビジネスモデルの観点からは非常に興味深い考察ですが、実際の実装時にはいくつかの実行上の困難も巨大である可能性があります。例えば、これらの演算間でどのように調整して完全な証明を生成するか、少なくともフェーズIにおいて時間やコストで劣らない必要があります。
フェーズIII:誰もがProverを実行する
将来的には、Proverがユーザーのローカル(ウェブ端末またはモバイル端末)で実行されることになります。Zprizeは、WebAssembly/Android実行環境に基づくZKP加速に関連する競技と報酬を提供しており、これは一定の程度でユーザーのプライバシーが確保されることを意味します(現在の中央集権的Proverは拡張のためだけであり、ユーザーのプライバシーを保証しません)。最も重要な点は、ここでのプライバシーはチェーン上の行動だけでなく、チェーン外の行動も含まれます。
考慮すべき必須の問題は、ウェブ端末の安全性に関するもので、ウェブ端末の実行環境はハードウェアに比べて安全性の前提条件が高くなります(業界のウィットネスとして、metmaskのようなウェブ端末ウォレットはハードウェアウォレットに比べて安全性が低いです)。
チェーン上のデータをチェーン外で証明するだけでなく、ZKPの形式でチェーン外データをチェーン上にアップロードし、ユーザーのプライバシーを100%保護することができるのは、このフェーズでのみ成立する可能性があります。現在の解決策は、避けられないことに二つの問題に直面しています - 1. 中央集権化、つまりユーザーの情報が依然として検閲のリスクにさらされること 2. 検証可能なデータ形式が単一であること。チェーン外データは多様で非標準化されており、検証可能なデータ形式は大量の洗浄/スクリーニングを経る必要があり、依然として形式が単一です。
ここでの課題は、証明生成の環境だけでなく、アルゴリズムレベルで互換性があるかどうか(まずは透明なアルゴリズムを使用する必要があります)、およびコスト/時間/効率についても考慮する必要があります。しかし、同時に需要も比類のないものであり、現実生活の信用を分散化された方法で担保し、チェーン上で貸し出しを行い、検閲のリスクがないことを想像してみてください。
 リスク警告
リスク警告 リスク警告
リスク警告